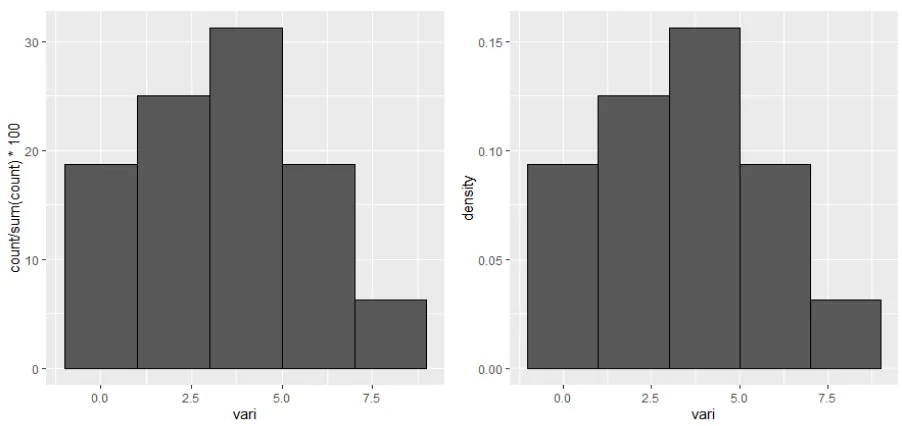
library(ggplot2)
data = diamonds[, c('carat', 'color')]
data = data[data$color %in% c('D', 'E'), ]
我想比较D和E颜色的克拉直方图,并在y轴上使用类别百分比。 我尝试过的解决方案如下:
解决方案1:
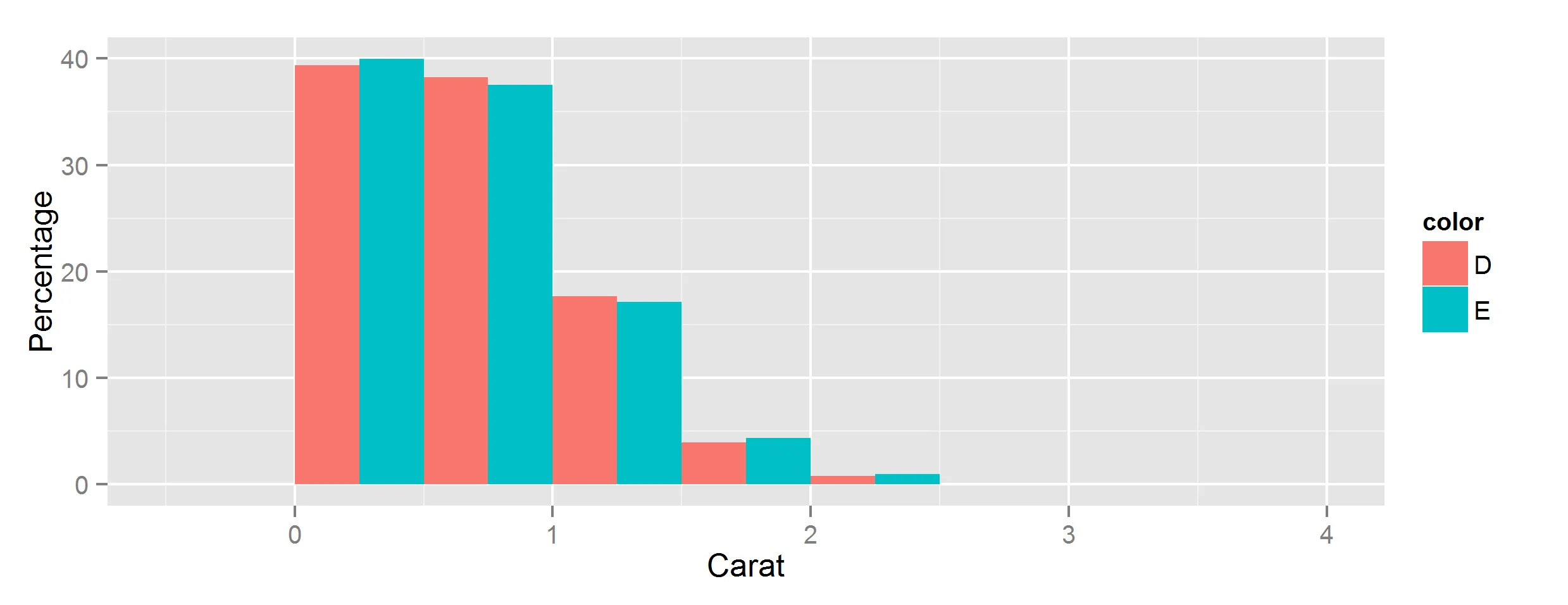
ggplot(data=data, aes(carat, fill=color)) + geom_bar(aes(y=..density..), position='dodge', binwidth = 0.5) + ylab("Percentage") +xlab("Carat")
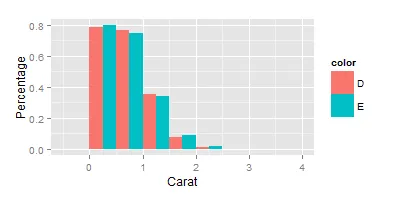
这不太准确,因为y轴显示的是估计密度的高度。
解决方案2:
ggplot(data=data, aes(carat, fill=color)) + geom_histogram(aes(y=(..count..)/sum(..count..)), position='dodge', binwidth = 0.5) + ylab("Percentage") +xlab("Carat")
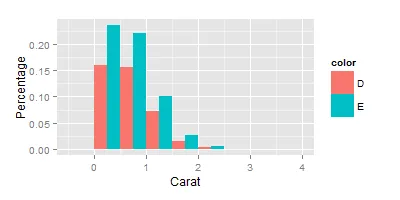
这也不是我想要的,因为用于在y轴上计算比率的分母是D + E的总计数。
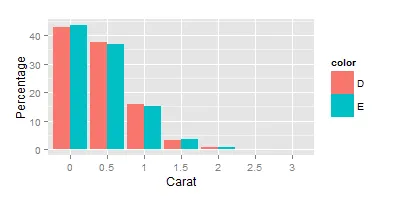
是否有一种方法可以使用ggplot2的堆积直方图来显示按类别划分的百分比?也就是说,不是显示bin中obs的数量/ count(D + E)在y轴上,而是分别显示bin中obs的数量/ count(D)和bin中obs的数量/ count(E)对于两个颜色类。谢谢。