我最近开始深入研究pandas,并希望可视化一些包含间隙的时间序列数据,其中一些间隙相当大。以下是一个示例mydf:
timestamp val
0 2016-07-25 00:00:00 0.740442
1 2016-07-25 01:00:00 0.842911
2 2016-07-25 02:00:00 -0.873992
3 2016-07-25 07:00:00 -0.474993
4 2016-07-25 08:00:00 -0.983963
5 2016-07-25 09:00:00 0.597011
6 2016-07-25 10:00:00 -2.043023
7 2016-07-25 12:00:00 0.304668
8 2016-07-25 13:00:00 1.185997
9 2016-07-25 14:00:00 0.920850
10 2016-07-25 15:00:00 0.201423
11 2016-07-25 16:00:00 0.842970
12 2016-07-25 21:00:00 1.061207
13 2016-07-25 22:00:00 0.232180
14 2016-07-25 23:00:00 0.453964
现在我可以通过df1.plot(x='timestamp').get_figure().show()绘制我的数据框,并且沿x轴的数据将被插值(显示为一条线):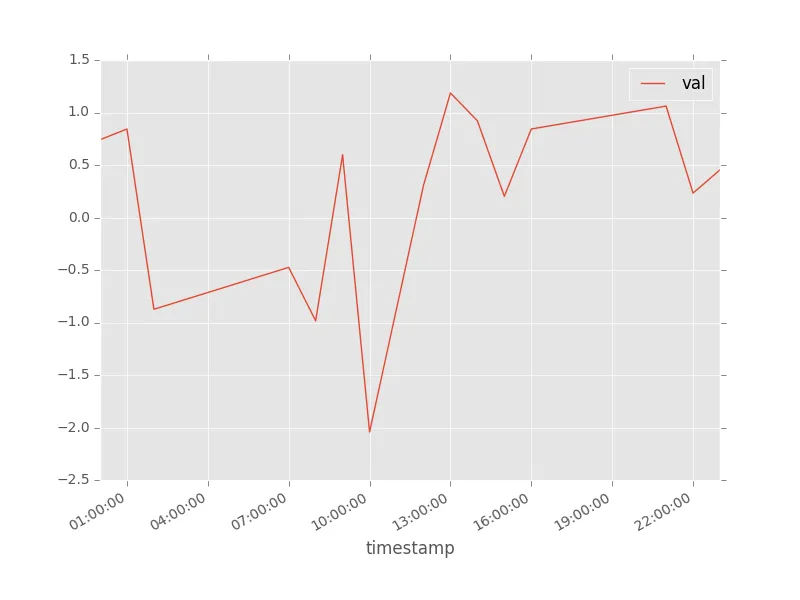
但我想要的是:
- 数据区段之间有可见的间隙
- 不同间隙长度有一致的间隙宽度
- 可能在轴上加入某种标记,以帮助说明时间跳跃的情况。
在这方面进行研究,我发现了以下内容:
这些方法都接近我想要的,但前一种方法只会在绘制的图形中留下缺口,后一种方法则会产生我想要避免的大间隙(考虑到间隙甚至可能跨越几天)。
由于第二种方法可能更接近我想要的结果,因此我尝试使用我的时间戳列作为索引:
mydf2 = pd.DataFrame(data=list(mydf['val']), index=mydf[0])
通过重新索引,我可以使用NaN填补空缺(想知道是否有更简单的解决方案):
mydf3 = mydf2.reindex(pd.date_range('25/7/2016', periods=24, freq='H'))
导致:
val
2016-07-25 00:00:00 0.740442
2016-07-25 01:00:00 0.842911
2016-07-25 02:00:00 -0.873992
2016-07-25 03:00:00 NaN
2016-07-25 04:00:00 NaN
2016-07-25 05:00:00 NaN
2016-07-25 06:00:00 NaN
2016-07-25 07:00:00 -0.474993
2016-07-25 08:00:00 -0.983963
2016-07-25 09:00:00 0.597011
2016-07-25 10:00:00 -2.043023
2016-07-25 11:00:00 NaN
2016-07-25 12:00:00 0.304668
2016-07-25 13:00:00 1.185997
2016-07-25 14:00:00 0.920850
2016-07-25 15:00:00 0.201423
2016-07-25 16:00:00 0.842970
2016-07-25 17:00:00 NaN
2016-07-25 18:00:00 NaN
2016-07-25 19:00:00 NaN
2016-07-25 20:00:00 NaN
2016-07-25 21:00:00 1.061207
2016-07-25 22:00:00 0.232180
2016-07-25 23:00:00 0.453964
从这里开始,我可能需要将一定数量的连续条目中缺失数据的条目减少到一个固定数字(表示我的间隙宽度),并对这些条目的索引值进行一些处理,使它们以不同的方式绘制,但是我在这里迷失了,因为我不知道如何实现这样的事情。
在摸索中,我想知道是否有更直接和优雅的方法,如果任何人对此了解更多,能够指引我朝着正确的方向发展,我将不胜感激。
提前感谢任何提示和反馈!
### 附录 ###
发布问题后,我遇到了另一个有趣的Idea postend by Andy Hayden,看起来很有帮助。他使用一个列来保存与时间差异的比较结果。在对布尔结果的int表示执行cumsum()之后,他使用groupby()将每个未间隔系列的条目聚合到一个DataFrameGroupBy对象中。
由于这是一段时间前写的,所以现在pandas返回timedelta对象,因此应该使用另一个timedelta对象进行比较,如下所示(基于上面的mydf或将其索引复制到现在的列中通过mydf2['timestamp'] = mydf2.index重新索引df2):
from datetime import timedelta
myTD = timedelta(minutes=60)
mydf['nogap'] = mydf['timestamp'].diff() > myTD
mydf['nogap'] = mydf['nogap'].apply(lambda x: 1 if x else 0).cumsum()
## btw.: why not "... .apply(lambda x: int(x)) ..."?
dfg = mydf.groupby('nogap')
我们现在可以遍历DataFrameGroup,获取未中断的序列,并对它们进行某些处理。我的pandas / mathplot技能还不够成熟,但我们是否可以将组元素绘制成子图?也许这样时间轴上的不连续性可以以某种方式表示(例如中断的轴线等)? piRSquared的答案已经得到了一个相当可用的结果,唯一有点遗漏的是需要更加引人注目的视觉反馈,说明在两个值之间发生了间隙/时间跳跃。
也许通过分组节可以更灵活地配置间距表示的宽度?
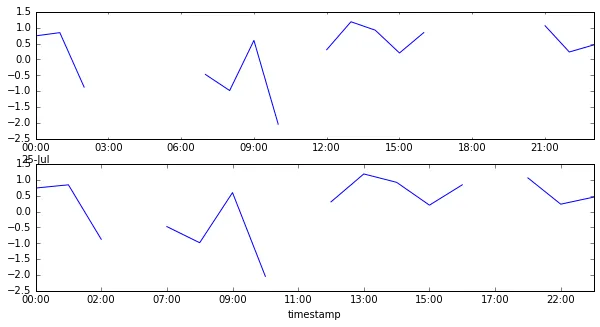
resample而不是reindex似乎是个好主意,还有在notnull()中加上ffill的巧妙运用。我猜我需要更仔细地研究如何处理子图以理解最后一部分... - antiplex