I have a timeseries dataframe of the form:
rng = pd.date_range('1/1/2013', periods=1000, freq='10min')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts = ts.to_frame(name=None)
我需要做两件事情:
步骤1:修改索引,使每天从前一天的17:00:00开始。我使用以下方法完成此操作:
ts.index = pd.to_datetime(ts.index.values + np.where((ts.index.time >= datetime.time(17)), pd.offsets.Day(1).nanos, 0))
步骤2:像这样旋转数据框:
ts_ = pd.pivot_table(ts, index=ts.index.date, columns=ts.index.time, values=0)
我遇到的问题是,在对数据框进行透视时,Pandas好像忘记了我在步骤1中所做的索引修改。
以下是示例内容:
00:00:00 00:10:00 00:20:00 ... 23:50:00
2013-01-10 -1.800381 -0.459226 -0.172929 ... -1.000381
2013-01-11 -1.258317 -0.973924 0.955224 ... 0.072929
2013-01-12 -0.834976 0.018793 -0.141608 ... 2.072929
2013-01-13 -0.131197 0.289998 2.200644 ... 1.589998
2013-01-14 -0.991653 0.276874 -1.390654 ... -2.090654
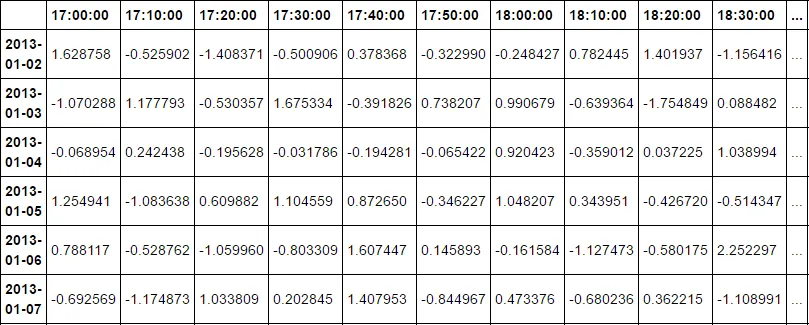
相反,这是期望的结果。
17:00:00 17:10:00 17:20:00 ... 16:50:00
2013-01-10 -2.800381 1.000226 2.172929 ... 0.172929
2013-01-11 0.312587 1.003924 2.556624 ... -0.556624
2013-01-12 2.976834 1.000003 -2.141608 ... -1.141608
2013-01-13 1.197131 1.333998 -2.999944 ... -1.999944
2013-01-14 -1.653991 1.278884 -1.390654 ... -4.390654
使用Python 2.7 注意: Nickil Maveli 提出的解决方案近似正确,但是日期偏移方向不对。理念是Day_t = Day_t-1在'17:00'开始。目前,该解决方案将Day_t = 在'17:00'开始的Day_t。