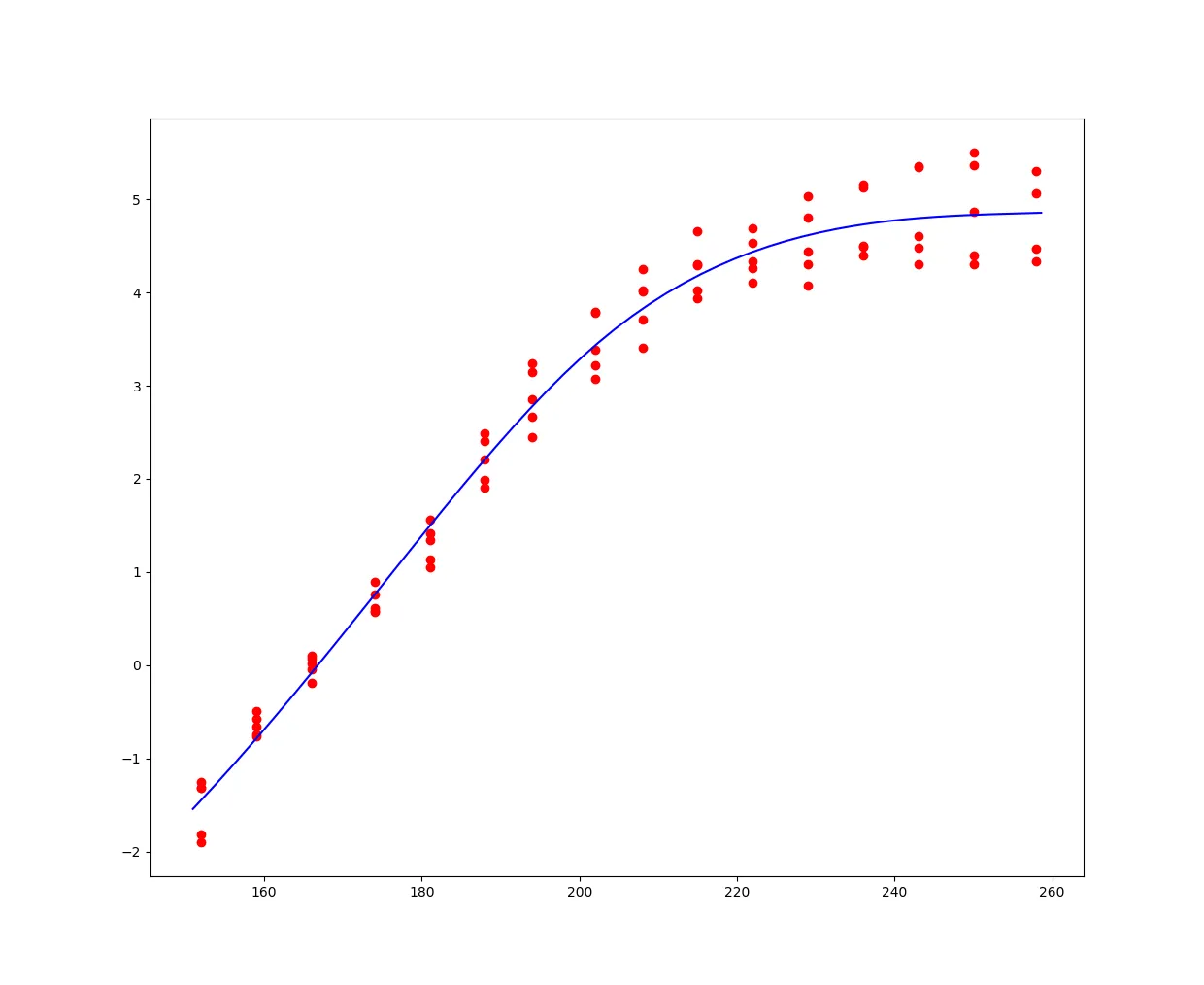
scipy UnivariateSpline不允许出现多值X。我看到有人说这个问题已经解决了,但是对我似乎没有用。我正在使用最新版本,刚刚使用pip尝试下载,显示我已经拥有最新版本。
我尝试将s(平滑参数)从0和None(X必须严格递增)更改,但这并没有解决问题。
import matplotlib.pyplot as plt
from scipy.interpolate import UnivariateSpline
x=[152,152,152,152,152,159,159,159,159,159,166,166,166,166,166,174,174,174,174,174,181,181,181,181,181,188,188,188,188,188,194,194,194,194,194,202,202,202,202,202,208,208,208,208,208,215,215,215,215,215,222,222,222,222,222,229,229,229,229,229,236,236,236,236,236,243,243,243,243,243,250,250,250,250,250,258,258,258,258]
y=[-1.31639523,-1.90045889,-1.81769285,-1.25702203,-1.31975784,-0.76206863,-0.74170737,-0.66029284,-0.58124809,-0.49593701,-0.19309943,0.02254396,-0.04614866,0.06709774,0.10436002,0.577175,0.56809403,0.89547559,0.60922195,0.76220672,1.0461253,1.1304339,1.56360338,1.34189828,1.41658105,1.98677786,2.40487089,2.20431052,1.91072699,2.49328809,2.670556,2.85024397,3.24333426,2.44841554,3.14604703,3.39128172,3.78063788,3.21446612,3.07158159,3.79503965,3.40717945,4.02417242,3.70708767,4.00729682,4.25504517,4.28874564,3.9356614,4.30337567,4.02388633,4.65376986,4.33884509,4.68839858,4.10508666,4.26236997,4.53098529,5.03443645,4.07940011,4.3033351,4.43476139,4.80221614,4.49558967,4.5052504,4.40289487,5.15433152,5.1330299,4.30299696,4.47974301,5.34886789,4.60896298,5.35997675,4.40204983,5.50162549,4.3056854,4.87120463,5.36265274,4.33578634,5.06347439,4.46811258,5.30920785]
s = 0.1 # set smoothing to non-zero
spl = UnivariateSpline(x, y, s=s)
我收到了这个错误信息:
-
spl = UnivariateSpline(x, y, s=s)
File "C:\Python37\lib\site-packages\scipy\interpolate\fitpack2.py", line 177, in __init__
raise ValueError('x must be strictly increasing')
ValueError: x must be strictly increasing.
欢迎提供任何帮助或建议!