我有一系列包含ACGTE字母的长度不同的序列,共有n=400个。例如,在A后出现C的概率为:
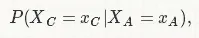
可以从经验序列集计算得出。

假设:
那么我可以得到一个转移矩阵:
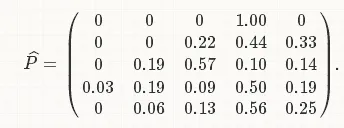
但是我想计算Phat的置信区间,你有什么想法吗?
可以从经验序列集计算得出。
假设:
那么我可以得到一个转移矩阵:
但是我想计算Phat的置信区间,你有什么想法吗?
bootci函数。以下是一个示例:%# generate a random cell array of 400 sequences of varying length
%# each containing indices from 1 to 5 corresponding to ACGTE
sequences = arrayfun(@(~) randi([1 5], [1 randi([500 1000])]), 1:400, ...
'UniformOutput',false)';
%# compute transition matrix from all sequences
trans = countFcn(sequences);
%# number of bootstrap samples to draw
Nboot = 1000;
%# estimate 95% confidence interval using bootstrapping
ci = bootci(Nboot, {@countFcn, sequences}, 'alpha',0.05);
ci = permute(ci, [2 3 1]);
>> trans %# 5x5 transition matrix: P_hat
trans =
0.19747 0.2019 0.19849 0.2049 0.19724
0.20068 0.19959 0.19811 0.20233 0.19928
0.19841 0.19798 0.2021 0.2012 0.20031
0.20077 0.19926 0.20084 0.19988 0.19926
0.19895 0.19915 0.19963 0.20139 0.20088
另外还有两个类似的矩阵,其中包含置信区间的下限和上限:
>> ci(:,:,1) %# CI lower bound
>> ci(:,:,2) %# CI upper bound
function trans = countFcn(seqs)
%# accumulate transition matrix from all sequences
trans = zeros(5,5);
for i=1:numel(seqs)
trans = trans + sparse(seqs{i}(1:end-1), seqs{i}(2:end), 1, 5,5);
end
%# normalize into proper probabilities
trans = bsxfun(@rdivide, trans, sum(trans,2));
end
bootstrp函数来获取从每个自助采样中计算出的统计量,我们用它来显示转换矩阵中每个条目的直方图:%# compute multiple transition matrices using bootstrapping
stat = bootstrp(Nboot, @countFcn, sequences);
%# display histogram for each entry in the transition matrix
sub = reshape(1:5*5,5,5);
figure
for i=1:size(stat,2)
subplot(5,5,sub(i))
hist(stat(:,i))
end
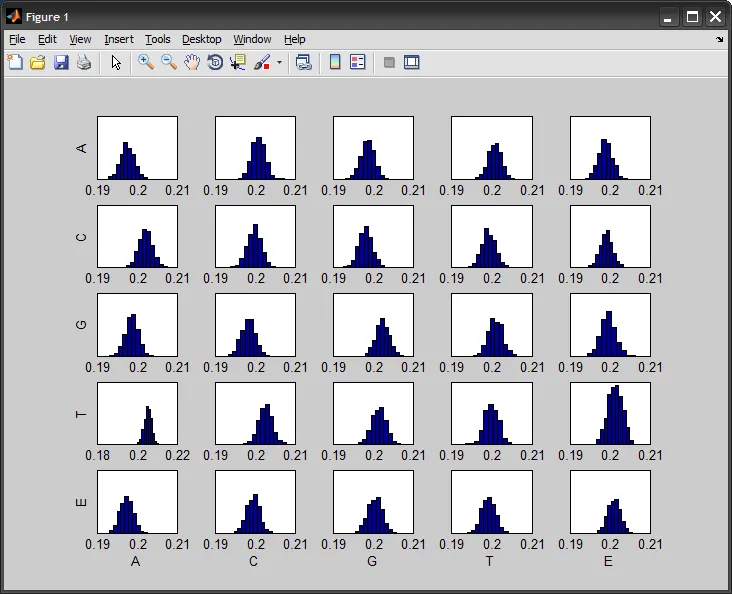
P_hat,每行的和确实应该为一(精度有限)。在计算函数countFcn中,我首先累积了每个序列中共现的计数(使用较少知道的sparse函数的语法,但我们也可以使用accumarray),然后我通过行求和进行了除法(bsxfun调用)。一个注意事项:如果一个符号没有出现在一个序列中(比如我们只有[1 2 4 5]),那么我们可能会被零除,导致转移矩阵中出现NaN值。一个常见的解决方案是在对行进行归一化之前将整个矩阵加上+1。 - Amrobootstrp的输出中计算出来,方法是:C = cov(stat)。stat的每一行都是一个展平的5x5转移矩阵,来自于抽取样本中的一个。cov作用于输入矩阵的列,结果将是一个25x25的矩阵,对应于P_hat每对条目之间的协方差。 - Amro我不确定这个方法在统计上是否可靠,但获取指示性的上下界的简单方法如下:
将样本分成n个相等的部分(例如1:40,41:80,...,361:400),并为每个子样本计算概率矩阵。
通过观察概率在子样本中的分布,您应该能够很好地了解方差。
这种方法的缺点是可能无法实际计算出具有所需给定概率的区间。优点是它应该能够让您很好地了解序列的行为,并且它可能会捕捉到其他基于假设的方法(例如自助法)由于假设而丢失的一些信息。