马尔可夫链模型和隐马尔可夫模型有什么区别?我在维基百科上看了,但是没看懂它们的区别。
马尔可夫链和隐马尔可夫模型有什么区别?
62
- good_evening
4
你应该考虑接受下面得票最多的答案。 - Ron
我建议将这种问题发到“https://math.stackexchange.com”,因为它不是一个关于编程的问题。然而,简单回答你的问题是,马尔可夫链与HMM的隐藏部分相同。主要区别在于,HMM有一个矩阵将观测连接到状态,而在马尔可夫链中,我们不考虑任何观测。 - Koorosh Aslansefat
2@KooroshAslansefat我建议检查问题的日期。 - good_evening
是的,你说得对。我没有检查问题的日期。 - Koorosh Aslansefat
5个回答
51
举个例子来解释,我会使用自然语言处理中的一个例子。想象一下你想知道这个句子的概率:
I enjoy coffee
在马尔科夫模型中,您可以通过计算来估算它的概率:
P(WORD = I) x P(WORD = enjoy | PREVIOUS_WORD = I) x P(word = coffee| PREVIOUS_WORD = enjoy)
现在,想象一下我们想知道这个句子的词性标记,也就是一个单词是过去时动词、名词等。我们没有在那个句子中观察到任何词性标记,但我们假设它们存在。因此,我们计算词性标记序列的概率。在我们的案例中,实际序列是:
PRP-VBP-NN
(其中 PRP=“人称代词”,VBP=“动词,非第三人称单数现在时”,NN=“名词,单数或大量”。有关Penn POS标记的完整符号,请参见https://cs.nyu.edu/grishman/jet/guide/PennPOS.html)
但等等!这是一个我们可以应用马尔可夫模型的序列。但我们称其为隐藏的,因为词性标记序列从未直接观察到。当然,在实践中,我们会计算许多这样的序列,并希望找到最好解释我们观察到的隐藏序列(例如,我们更有可能看到像'the'、'this'这样的单词,生成自限定词(DET)标记)
我曾经遇到的最好的解释是由劳伦斯·R·拉宾纳(Lawrence R. Rabiner)在1989年的一篇论文中提出的:http://www.cs.ubc.ca/~murphyk/Bayes/rabiner.pdf
- matt
2
你好 @matt,能否解释一下 PRP-VBP-NN 这部分是什么意思?它代表什么? - user4061624
由于其他人可能也会有这个问题,所以我已经更新了答案。 - matt
31
马尔可夫模型是一个状态机,其状态转换的基础是概率。在隐马尔科夫模型中,您不知道概率值,但您知道结果。
例如,当您抛硬币时,您可以得到概率值,但是如果您看不到硬币翻转并且有人在每次硬币翻转时移动五个手指之一,您可以使用隐马尔可夫模型获取硬币翻转的最佳猜测。
- TechEffigy
24
据我理解,问题是:马尔可夫过程和隐马尔可夫过程有什么区别?
马尔可夫过程(MP)是一种随机过程,具有以下特点:
- 有限数量的状态
- 这些状态之间的转换是概率性的
- 下一个状态仅由当前状态决定(马尔可夫性质)
隐马尔可夫过程(HMM)也是一种随机过程,具有以下特点:
- 有限数量的状态
- 这些状态之间的转换是概率性的
- 下一个状态仅由当前状态决定(马尔可夫性质)并且
- 我们不确定处于哪个状态:当前状态发出观察结果。
例子 - (HMM)股票市场:
在股票市场上,人们根据公司的价值进行交易。假设股票的真实价值为100美元(这是不可观测的,事实上你永远不会知道它)。你真正看到的是它被交易的价值:在这种情况下,假设为90美元(这是可观测的)。
对于对马尔可夫感兴趣的人:有趣的部分是当你开始在这些模型上采取行动时(在前面的例子中,为了赚钱)。这就涉及到马尔可夫决策过程(MDP)和部分可观察马尔可夫决策过程(POMDP)。为了评估这些模型的一般分类,我总结了以下图片中每个马尔可夫模型的主要特征。
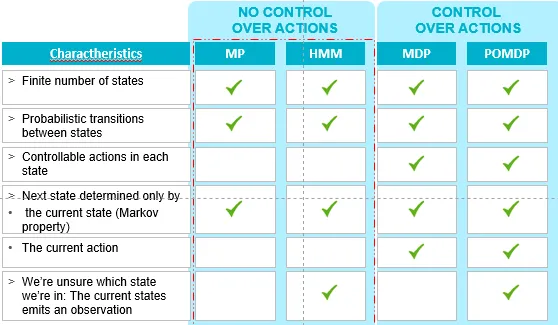
- Carles
1
请查看此链接获取关于马尔科夫链和隐马尔科夫模型的区别的确切信息:https://newbedev.com/what-is-the-difference-between-markov-chains-and-hidden-markov-model - Channa
11
由于Matt使用词性标记作为HMM的示例,我可以再举一个例子:语音识别。几乎所有大量词汇连续语音识别(LVCSR)系统都基于HMM。
"Matt的例子": 我喜欢咖啡
在马尔可夫模型中,您可以通过计算其概率来估计它:
P(WORD = I) x P(WORD = enjoy | PREVIOUS_WORD = I) x P(word = coffee| PREVIOUS_WORD = enjoy)
在一个隐马尔可夫模型中,
假设有30个不同的人读出句子"I enjoy hugging",我们需要识别它。每个人发音都不同。因此,我们不知道这个人是指"拥抱"还是"占为己有"。我们只有实际单词的概率分布。
简而言之,隐马尔可夫模型是一种统计马尔可夫模型,假设被建模的系统是具有未观察到(隐藏)状态的马尔可夫过程。
- aerin
-1
隐马尔可夫模型是双重嵌入式随机过程,有两个层次。
上层是一个马尔可夫过程,状态是不可观测的。
事实上,观察结果是上层马尔可夫状态的概率函数。
不同的马尔可夫状态将具有不同的观测概率函数。
上层是一个马尔可夫过程,状态是不可观测的。
事实上,观察结果是上层马尔可夫状态的概率函数。
不同的马尔可夫状态将具有不同的观测概率函数。
- sahel
3
14"整个答案都应该用引号,并参考 Rabiner 的教程。" - Zhubarb
2这真的很难理解。 - goelakash
2这并没有回答问题,你只是引用了每个条目文本到HMMs。 - Astrid
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接