给定:
 以及以下内容:
以及以下内容:
 对于:
对于:
以及以下内容:
对于:q(runs | the, dog) = 0.5
这里应该是 1,因为对于q(runs | the, dog)来说:xi=runs, xi-2=the, xi-1=dog。
概率值(wi已被替换为xi):
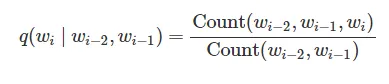
所以:
count(the dog runs) / count(the dog) = 1 / 1 = 1
但在上面的例子中,值为0.5。0.5是如何得出的?
根据http://files.asimihsan.com/courses/nlp-coursera-2013/notes/nlp.html#markov-processes-part-1。