我将尝试用MultivariateStats.jl包在Julia中执行简单的探索性PCA。例如,在R中,您可以执行以下操作:
一旦我获取了PCA“模型”
据我所知,从准机器学习的角度来看,Julia实现了PCA作为“模型”,基本上没有办法轻松地显示所有通常需要在探索性PCA中使用的图形、统计和见解(我的意思是cos²、贡献等)。
是否有其他Julia包更加面向探索性多元分析,能够提供类似于著名的R软件包FactoMineR或ade4的粗略等效物?
谢谢!
library(FactoMineR)
data(iris)
## PCA model:
res_pca <- PCA(iris, quali.sup = 5, graph = FALSE)
## Retrieve coordinates of individuals on all 4 PCs:
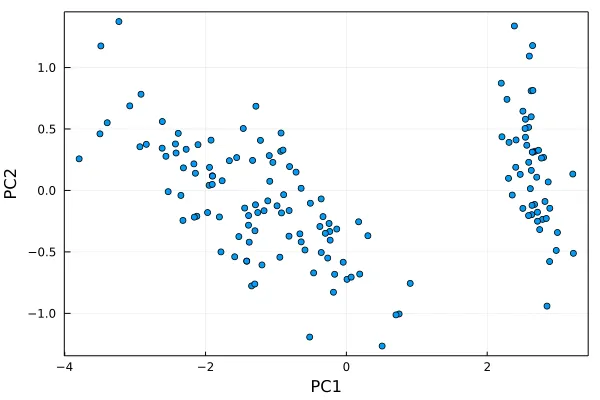
res_pca$ind$coord
## Simple plots:
plot(res_pca, choix = "ind", habillage = 5)
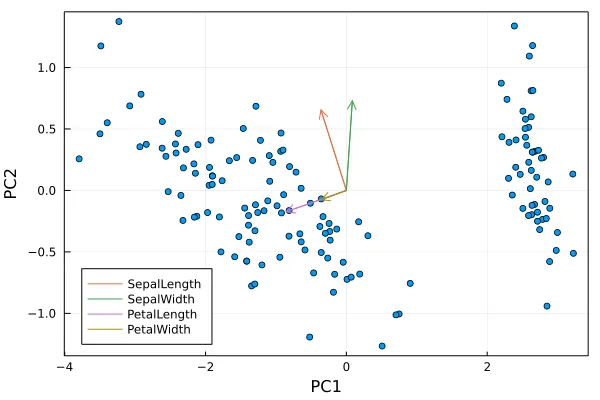
plot(res_pca, choix = "var")
我无法在Julia中找到这些非常基本的操作的等效方法(使用MultivariateStats.jl的“本地”函数)。让我们从以下内容开始:
using MultivariateStats
using RDatasets
iris = dataset("datasets", "iris")
## PCA model:
M = fit(PCA, Array(iris[:, 1:4]); pratio=1, maxoutdim=4)
一旦我获取了PCA“模型”
M,如何轻松检索个体坐标?如何轻松显示相关圆等内容?据我所知,从准机器学习的角度来看,Julia实现了PCA作为“模型”,基本上没有办法轻松地显示所有通常需要在探索性PCA中使用的图形、统计和见解(我的意思是cos²、贡献等)。
是否有其他Julia包更加面向探索性多元分析,能够提供类似于著名的R软件包FactoMineR或ade4的粗略等效物?
谢谢!