我正在学习使用PyTesser和Tesseract进行OCR。作为第一个里程碑,我想编写一个工具来识别仅由一些数字组成的验证码。我阅读了一些教程并编写了这样的测试程序。
from pytesser.pytesser import *
from PIL import Image, ImageFilter, ImageEnhance
im = Image.open("test.tiff")
im = im.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(2)
im = im.convert('1')
text = image_to_string(im)
print "text={}".format(text)
I tested my code with the image below. But the result is 2(T?770. And I've tested some other similar images as well, in 80% case the results are incorrect.
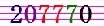
I'm not familiar with imaging processing. I've two questions here:
Is it possible to tell
PyTesserto guess digits only?I think the image is quite easy for human to read. If it is so difficult for
PyTesserto read digits only image, is there any alternatives can do a better OCR?
Any hints are very appreciated.