简单的问题。当我通过pytesser运行这个图片(链接已失效)时,我得到了
编辑
所以...我的代码生成类似于上面链接的图片,只是数字不同,并且应该解决简单的数学问题,但如果我从图片中获取的只有
这是我目前使用的代码:
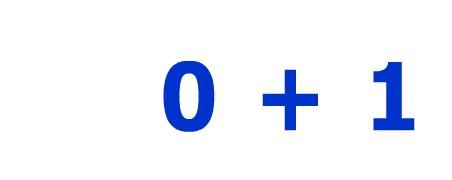{kind=link}
$+s。我该如何解决?编辑
所以...我的代码生成类似于上面链接的图片,只是数字不同,并且应该解决简单的数学问题,但如果我从图片中获取的只有
$+s,这显然是不可能的。这是我目前使用的代码:
from pytesser import *
time.sleep(2)
i = 0
operator = "+"
while i < 100:
time.sleep(.1);
img = ImageGrab.grab((349, 197, 349 + 452, 197 + 180))
equation = image_to_string(img)
接下来我将开始解析equation...只要我让pytesser工作起来。