我正在使用PyTesser来破解一个验证码。 PyTesser使用tesseract Python ocr库。在将图像放入PyTesser之前,我会使用一些过滤器。我的代码逐步如下:
输入图像为: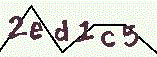
from PIL import Image
img = Image.open('1.gif')
img = img.convert("RGBA")
pixdata = img.load()
# Clean the background noise, if color != black, then set to white.
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][0] < 90:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][2] < 136:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][3] > 0:
pixdata[x, y] = (255, 255, 255, 255)
img.save("input-black.gif", "GIF")
应用此代码后的输出结果如下:
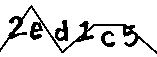
现在,
im_orig = Image.open('input-black.gif')
big = im_orig.resize((116, 56), Image.NEAREST)
ext = ".tif"
big.save("input-NEAREST" + ext)
在这段代码片段之后,输出的图像如下:
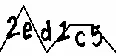
最后,当我应用这个
from pytesser import *
image = Image.open('input-NEAREST.tif')
print image_to_string(image)
我得到的输出是%/ww
请帮我找到正确的结果。
如果我使用这些图像,此代码可以成功识别字母。

