我正在尝试分析视频中的页面页脚并检索当前页码。我已经让帧集合工作了,但是我在使用EasyOCR读取页码本身时遇到了困难。
我已经尝试使用pytesseract,但它效果不佳。我误解了数字:10被识别为113,6被识别为41等等。总体来说,即使我正确地使用灰度、阈值和裁剪(只分析页脚的页码区域)格式化我的输入图像,结果仍然不一致。
以下是代码:
这让我得到了以下输出:
编辑:
在尝试对数字图像进行一些优化后,我现在回到了最初状态,根本不对图像进行优化。剩下的只是将其转换为灰度并调整大小。
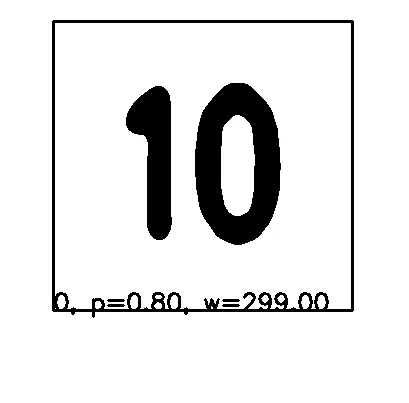
这是一个正常输入的样子:
“我尝试了去模糊、二值化、使用cv2.filter2D()进行去噪、模糊处理等等。”
“例如,当我使用二值化时,我的输出看起来像这样(忽略“1”,单个数字“1”同样适用):”
我已经尝试使用pytesseract,但它效果不佳。我误解了数字:10被识别为113,6被识别为41等等。总体来说,即使我正确地使用灰度、阈值和裁剪(只分析页脚的页码区域)格式化我的输入图像,结果仍然不一致。
以下是代码:
def getPageNumberTest(path, psm):
image = cv2.imread(path)
height = len(image)
width = len(image[0])
# the height of the footer
footerHeight = 90 # int(height / 15.5)
# retrieve only the footer from the image
cropped = image[height-footerHeight:height,0:width]
results = reader.readtext(cropped)
这让我得到了以下输出:

编辑:
在尝试对数字图像进行一些优化后,我现在回到了最初状态,根本不对图像进行优化。剩下的只是将其转换为灰度并调整大小。
这是一个正常输入的样子:

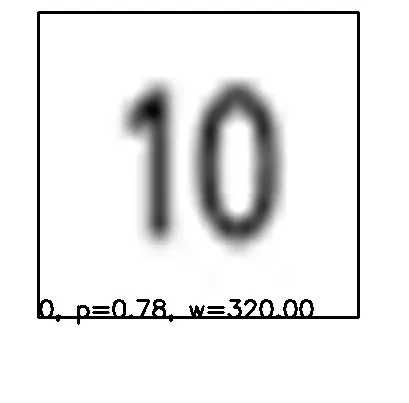
“我尝试了去模糊、二值化、使用cv2.filter2D()进行去噪、模糊处理等等。”
“例如,当我使用二值化时,我的输出看起来像这样(忽略“1”,单个数字“1”同样适用):”