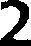我会尽力帮忙翻译。以下是您需要翻译的内容:
我尝试过以下方法: 但正如我之前所说,这些方法都存在问题。
我还尝试了查看每个图像中蓝色所占百分比的方法,但这些数字相差太小,无法通过观察其中的蓝色数量来区分数字。
所以我正在尝试创建一个程序,可以看到一幅图像上的数字,并在控制台中打印整数。(我使用的是python 3)
例如,程序应该能够识别下面这张图像(实际程序要检查的图像)是数字2:

我曾尝试使用cv2.matchTemplate()将其与另一张包含数字2的图像进行比较,但每次蓝色像素的RGB值都会有些不同,并且图像可能会稍微变大或变小。例如下面的图像:


我尝试过以下方法: 但正如我之前所说,这些方法都存在问题。
我还尝试了查看每个图像中蓝色所占百分比的方法,但这些数字相差太小,无法通过观察其中的蓝色数量来区分数字。
有人有解决方案吗?我使用cv2.matchTemplate()是很愚蠢的吗?是否有更简单的选项?(我不介意使用库,因为这是代码的一部分,但我更喜欢编写它,而不是使用库)