我正在使用Tesseract来识别使用手机相机拍摄的屏幕图片中的数字。我对图片进行了一些预处理:处理后的图片,并且使用Tesseract,我能够得到一些混合的结果。在上面的图片上运行以下代码,我得到以下输出:"EOE"。然而,在这张图片处理后的图片中,我得到了完全匹配的结果:"39:45.8"。
有什么方法可以获得更加一致的结果吗?
{kind=link}
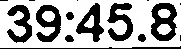{kind=link}
import cv2
import pytesseract
from PIL import Image, ImageEnhance
from matplotlib import pyplot as plt
orig_name = "time3.jpg";
image_name = "time3_.jpg";
img = cv2.imread(orig_name, 0)
img = cv2.medianBlur(img, 5)
img_th = cv2.adaptiveThreshold(img, 255,\
cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY, 11, 2)
cv2.imshow('image', img_th)
cv2.waitKey(0)
cv2.imwrite(image_name, img_th)
im = Image.open(image_name)
time = pytesseract.image_to_string(im, config = "-psm 7")
print(time)
有什么方法可以获得更加一致的结果吗?