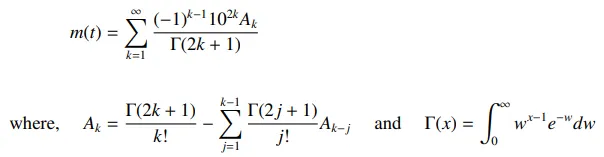好的,所以我最终在这方面采用了一种非常不同的方法。我已经实现了一个简单的离散化积分方程,它定义了更新函数:
m(t) = F(t) + integrate (m(t - s)*f(s), s, 0, t)
使用矩形法近似计算积分。对不同的t值进行积分近似,得到一个线性方程组。我编写了一个函数来生成方程,并从中提取系数矩阵。在查看一些示例后,我猜测了一个规则来直接定义系数,并用它来生成一些示例的解。特别是像OP的例子一样尝试形状=2,t=10,步长为0.1(因此有101个方程)。
我发现结果与我在一篇论文中发现的近似结果相当吻合(该论文在代码中引用了Baxter等人)。由于更新函数是事件数量的期望值,因此对于大的t,它近似等于t/mu,其中mu是事件之间的平均时间;这是知道我们是否处于附近的一种方便方式。
我正在使用Maxima(
http://maxima.sourceforge.net)进行工作,它不适用于数值处理,但使得尝试不同方面非常容易。此时,将最终的数值处理转换到另一种语言(如Python)将很简单。
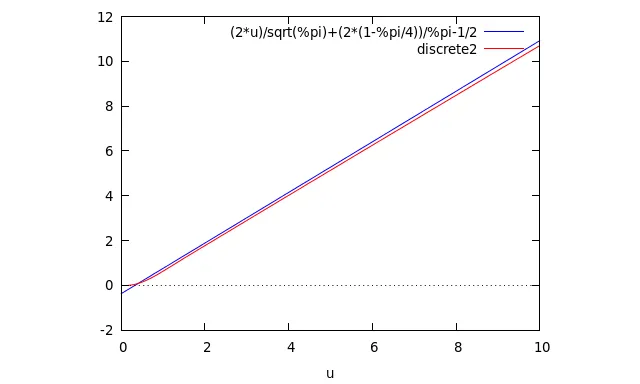
感谢 OP 提出这个问题,以及 S. Pappadeux 进行深入的讨论。下面是我得到的图表,将离散逼近(红色)与大 t 的逼近(蓝色)进行比较。尝试了一些不同步长的例子后,我发现随着步长变小,数值有点增加,因此我认为红线可能有点偏低,而蓝线可能更接近正确。
这是我的Maxima代码:
/* discretize weibull renewal function and formulate system of linear equations
* copyright 2020 by Robert Dodier
* I release this work under terms of the GNU General Public License
*
* This is a program for Maxima, a computer algebra system.
* http://maxima.sourceforge.net/
*/
"Definition of the renewal function m(t):" $
renewal_eq: m(t) = F(t) + 'integrate (m(t - s)*f(s), s, 0, t);
"Approximate integral equation with rectangle rule:" $
discretize_renewal (delta_t, k) :=
if equal(k, 0)
then m(0) = F(0)
else m(k*delta_t) = F(k*delta_t)
+ m(k*delta_t)*f(0)*(delta_t / 2)
+ sum (m((k - j)*delta_t)*f(j*delta_t)*delta_t, j, 1, k - 1)
+ m(0)*f(k*delta_t)*(delta_t / 2);
make_eqs (n, delta_t) :=
makelist (discretize_renewal (delta_t, k), k, 0, n);
make_vars (n, delta_t) :=
makelist (m(k*delta_t), k, 0, n);
"Discretized integral equation and variables for n = 4, delta_t = 1/2:" $
make_eqs (4, 1/2);
make_vars (4, 1/2);
make_eqs_vars (n, delta_t) :=
[make_eqs (n, delta_t), make_vars (n, delta_t)];
load (distrib);
subst_pdf_cdf (shape, scale, e) :=
subst ([f = lambda ([x], pdf_weibull (x, shape, scale)), F = lambda ([x], cdf_weibull (x, shape, scale))], e);
matrix_from (eqs, vars) :=
(augcoefmatrix (eqs, vars),
[submatrix (%%, length(%%) + 1), - col (%%, length(%%) + 1)]);
"Subsitute Weibull pdf and cdf for shape = 2 into discretized equation:" $
apply (matrix_from, make_eqs_vars (4, 1/2));
subst_pdf_cdf (2, 1, %);
"Just the right-hand side matrix:" $
rhs_matrix_from (eqs, vars) :=
(map (rhs, eqs),
augcoefmatrix (%%, vars),
[submatrix (%%, length(%%) + 1), col (%%, length(%%) + 1)]);
"Generate the right-hand side matrix, instead of extracting it from equations:" $
generate_rhs_matrix (n, delta_t) :=
[delta_t * genmatrix (lambda ([i, j], if i = 1 and j = 1 then 0
elseif j > i then 0
elseif j = i then f(0)/2
elseif j = 1 then f(delta_t*(i - 1))/2
else f(delta_t*(i - j))), n + 1, n + 1),
transpose (makelist (F(k*delta_t), k, 0, n))];
"Generate numerical right-hand side matrix, skipping over formulas:" $
generate_rhs_matrix_numerical (shape, scale, n, delta_t) :=
block ([f, F, numer: true], local (f, F),
f: lambda ([x], pdf_weibull (x, shape, scale)),
F: lambda ([x], cdf_weibull (x, shape, scale)),
[genmatrix (lambda ([i, j], delta_t * if i = 1 and j = 1 then 0
elseif j > i then 0
elseif j = i then f(0)/2
elseif j = 1 then f(delta_t*(i - 1))/2
else f(delta_t*(i - j))), n + 1, n + 1),
transpose (makelist (F(k*delta_t), k, 0, n))]);
"Solve approximate integral equation (shape = 3, t = 1) via LU decomposition:" $
fpprintprec: 4 $
n: 20 $
t: 1;
[AA, bb]: generate_rhs_matrix_numerical (3, 1, n, t/n);
xx_by_lu: linsolve_by_lu (ident(n + 1) - AA, bb, floatfield);
"Iterative solution of approximate integral equation (shape = 3, t = 1):" $
xx: bb;
for i thru 10 do xx: AA . xx + bb;
xx - (AA.xx + bb);
xx_iterative: xx;
"Should find iterative and LU give same result:" $
xx_diff: xx_iterative - xx_by_lu[1];
sqrt (transpose(xx_diff) . xx_diff);
"Try shape = 2, t = 10:" $
n: 100 $
t: 10 $
[AA, bb]: generate_rhs_matrix_numerical (2, 1, n, t/n);
xx_by_lu: linsolve_by_lu (ident(n + 1) - AA, bb, floatfield);
"Baxter, et al., Eq. 3 (for large values of t) compared to discretization:" $
/* L.A. Baxter, E.M. Scheuer, D.J. McConalogue, W.R. Blischke.
* "On the Tabulation of the Renewal Function,"
* Econometrics, vol. 24, no. 2 (May 1982).
* H(t) is their notation for the renewal function.
*/
H(t) := t/mu + sigma^2/(2*mu^2) - 1/2;
tx_points: makelist ([float (k/n*t), xx_by_lu[1][k, 1]], k, 1, n);
plot2d ([H(u), [discrete, tx_points]], [u, 0, t]), mu = mean_weibull(2, 1), sigma = std_weibull(2, 1);