我有一个像这样的数据集
dataset.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 79902 entries, 0 to 79901
Data columns (total 6 columns):
# Column Non-Null Count Dtype
0 Query 79902 non-null object
1 Video Title 79902 non-null object
2 Video ID 79902 non-null object
3 Video Views 79902 non-null object
4 Comment ID 79902 non-null object
5 cleaned_comments 79902 non-null object
dtypes: object(6)
memory usage: 5.5+ MB
使用编程语言移除了空值和NaN条目
dataset = dataset.replace(to_replace='None', value=np.nan).dropna()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 79868 entries, 0 to 79901
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Query 79868 non-null object
1 Video Title 79868 non-null object
2 Video ID 79868 non-null object
3 Video Views 79868 non-null object
4 Comment ID 79868 non-null object
5 cleaned_comments 79868 non-null object
dtypes: object(6)
memory usage: 6.1+ MB
注意条目减少了
但是视频观看次数是浮点数,如数据集.head()所示
然后我使用了
dataset['Video Views'] = pd.to_numeric(dataset['Video Views'])
dataset['Video Views'] = dataset['Video Views'].astype(int)
现在,
<class 'pandas.core.frame.DataFrame'>
Int64Index: 79868 entries, 0 to 79901
Data columns (total 6 columns):
# Column Non-Null Count Dtype
0 Query 79868 non-null object
1 Video Title 79868 non-null object
2 Video ID 79868 non-null object
3 Video Views 79868 non-null int64
4 Comment ID 79868 non-null object
5 cleaned_comments 79868 non-null object
dtypes: int64(1), object(5)
memory usage: 6.1+ MB
{kind=link}
{kind=link}
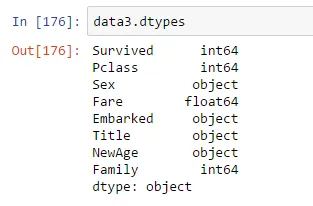
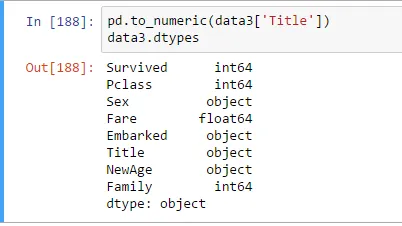
data3['Title'] = pd.to_numeric(data3['Title'])或者data3['Title'] data3['Title'].astype(int)。实际上应该有一个标准问题来解决这个问题,因为这种变体出现了无数次。 - EdChum