我希望拟合一个线性-平台(nls)模型,描述身高随年龄变化的关系,并测试模型参数在不同地区是否存在显著差异。
这是目前的进展:
# Create data
df1 <- cbind.data.frame (height = c (0.5, 0.6, 0.9, 1.3, 1.5, 1.6, 1.6,
0.6, 0.6, 0.8, 1.3, 1.5, 1.6, 1.5,
0.6, 0.8, 1.0, 1.4, 1.6, 1.6, 1.6,
0.5, 0.8, 1.0, 1.3, 1.6, 1.7, 1.6),
age = c (0.5, 0.9, 3.0, 7.3, 12.2, 15.5, 20.0,
0.4, 0.8, 2.3, 8.5, 11.5, 14.8, 21.3,
0.5, 1.0, 5.1, 11.1, 12.3, 16.0, 19.8,
0.5, 1.1, 5.5, 10.2, 12.2, 15.4, 20.5),
region = as.factor (c (rep ("A", 7),
rep ("B", 7),
rep ("C", 7),
rep ("D", 7))))
> head (df1)
height age region
1 0.5 0.5 A
2 0.6 0.9 A
3 0.9 3.0 A
4 1.3 7.3 A
5 1.5 12.2 A
6 1.6 15.5 A
# Create linear-plateau function
lp <- function(x, a, b, c){
ifelse (x < c, a + b * x, a + b * c)
} # Where 'a' is the intercept, 'b' the slope and 'c' the breakpoint
# Fit the model ignoring region
m1 <- nls (height ~ lp (x = age, a, b, c),
data = df1,
start = list (a = 0.5, b = 0.1, c = 13))
> summary (m1)
Formula: height ~ lp(x = age, a, b, c)
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 0.582632 0.025355 22.98 <2e-16 ***
b 0.079957 0.003569 22.40 <2e-16 ***
c 12.723995 0.511067 24.90 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.07468 on 25 degrees of freedom
Number of iterations to convergence: 2
Achieved convergence tolerance: 5.255e-09
我想要用相同的模型来考虑“region”,并测试“a”、“b”和“c”的估计值在不同地区是否不同。
我认为这篇帖子可能有用,但我不知道如何将其应用于此数据/函数。
以下是数据的外观:
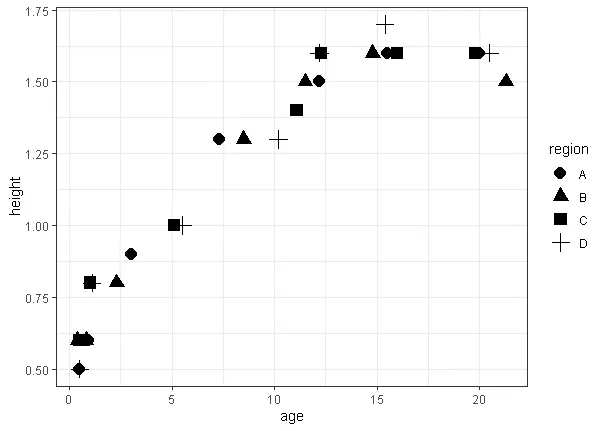
非使用nls的解决方案也受欢迎。