我正在尝试使用
我有一些简单的二维数据,大致呈三角函数形状。我希望使用
我的方法如下:
scipy.optimize.curve_fit 来拟合一些数据。我已经 阅读了文档,并且看过 这篇StackOverflow文章,但是两者都没有回答我的问题。我有一些简单的二维数据,大致呈三角函数形状。我希望使用
scipy 中的通用三角函数来拟合它。我的方法如下:
from __future__ import division
import numpy as np
from scipy.optimize import curve_fit
#Load the data
data = np.loadtxt('example_data.txt')
t = data[:,0]
y = data[:,1]
#define the function to fit
def func_cos(t,A,omega,dphi,C):
# A is the amplitude, omega the frequency, dphi and C the horizontal/vertical shifts
return A*np.cos(omega*t + dphi) + C
#do a scipy fit
popt, pcov = curve_fit(func_cos, t,y)
#Plot fit data and original data
fig = plt.figure(figsize=(14,10))
ax1 = plt.subplot2grid((1,1), (0,0))
ax1.plot(t,y)
ax1.plot(t,func_cos(t,*popt))
这将输出:
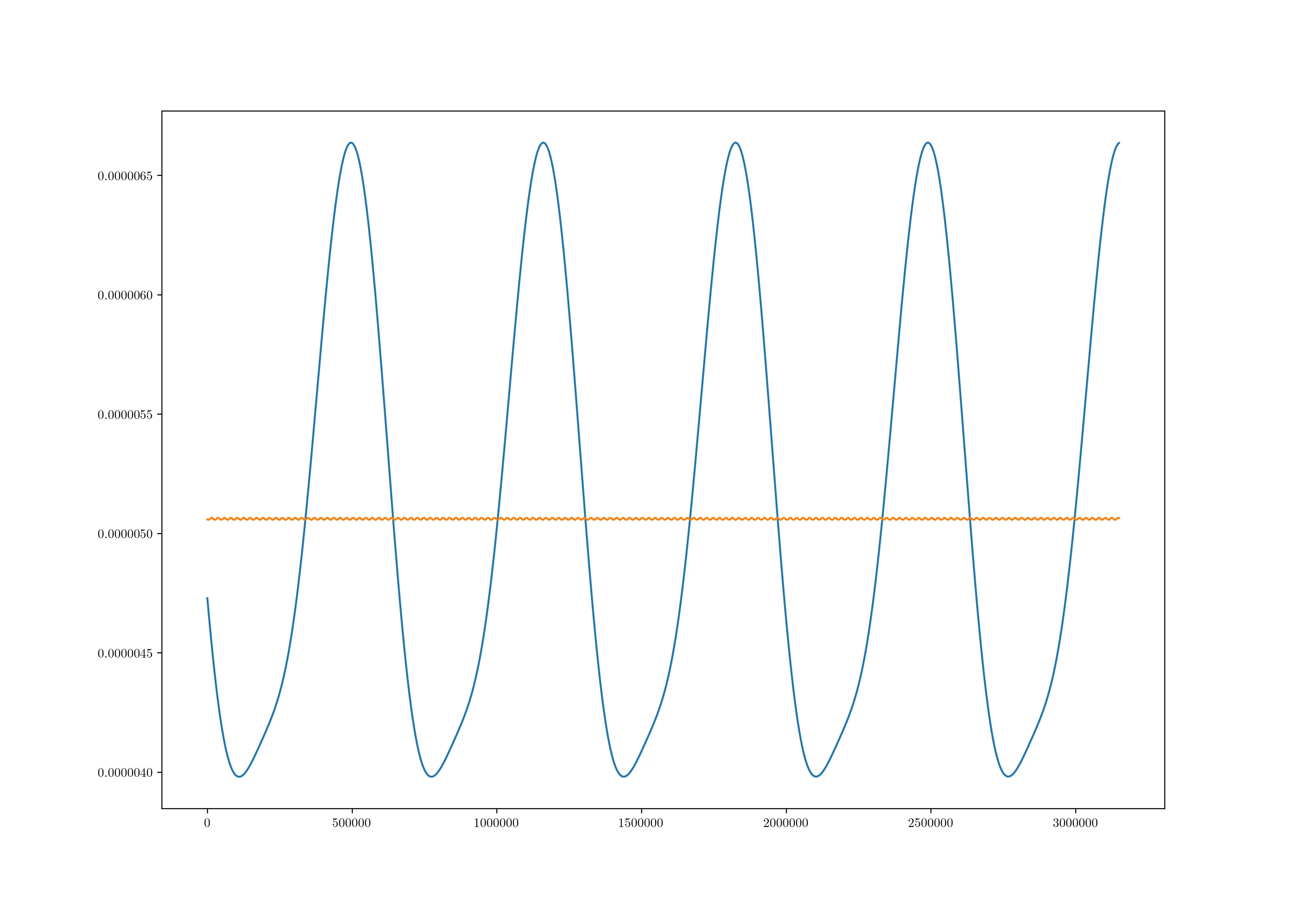
蓝色代表数据,橙色代表拟合结果。显然我做错了什么。有什么指点吗?
'example_data.txt'的样本数据,否则很难进行复制。 - a_guestsome_data超链接访问。 - user1887919