我想创建一个图表,显示每个“入职年份”(第一笔客户交易)的“累计平均收入”随时间变化的情况。但是在分组所需信息时我出现了错误。
玩具数据:
dataset = {'ClientId': [1,2,3,1,2,3,1,2,3,1,2,3,4,4,4,4,4,4,4],
'Year Onboarded': [2018,2019,2020,2018,2019,2020,2018,2019,2020,2018,2019,2020,2016,2016,2016,2016,2016,2016,2016],
'Year': [2019,2019,2020,2019,2019,2020,2018,2020,2020,2020,2019,2020,2016,2017,2018,2019,2020,2017,2018],
'Revenue': [100,50,25,30,40,50,60,100,20,40,100,20,5,5,8,4,10,20,8]}
df = pd.DataFrame(data=dataset)
解释:客户有指定的“加入年份”,并且每个提到的“年份”都会进行交易。然后我计算自客户上线以来经过的年数,以使我的图形更具视觉吸引力。
df['Yearsdiff'] = df['Year']-df['Year Onboarded']
为了计算累积平均收入,我尝试了以下方法:
- 第一次尝试:
df = df.join(df.groupby(['Year']).expanding().agg({ 'Revenue': 'mean'})
.reset_index(level=0, drop=True)
.add_suffix('_roll'))
df.groupby(['Year Onboarded', 'Year']).last().drop(columns=['Revenue'])
输出开始变成累积的了,但是最后一行不再是累积的(不确定原因)。
- 第二次尝试:
df.groupby(['Year Onboarded','Year']).agg('mean') \
.groupby(level=[1]) \
.agg({'Revenue':np.cumsum})
但它不能正常工作,我试过其他方法,但结果不尽如人意。
为了可视化累计平均收入,我只需使用sns.lineplot。
我的目标是获得类似于下面的图表,但为此我首先需要正确地对数据进行分组。
预期输出图表
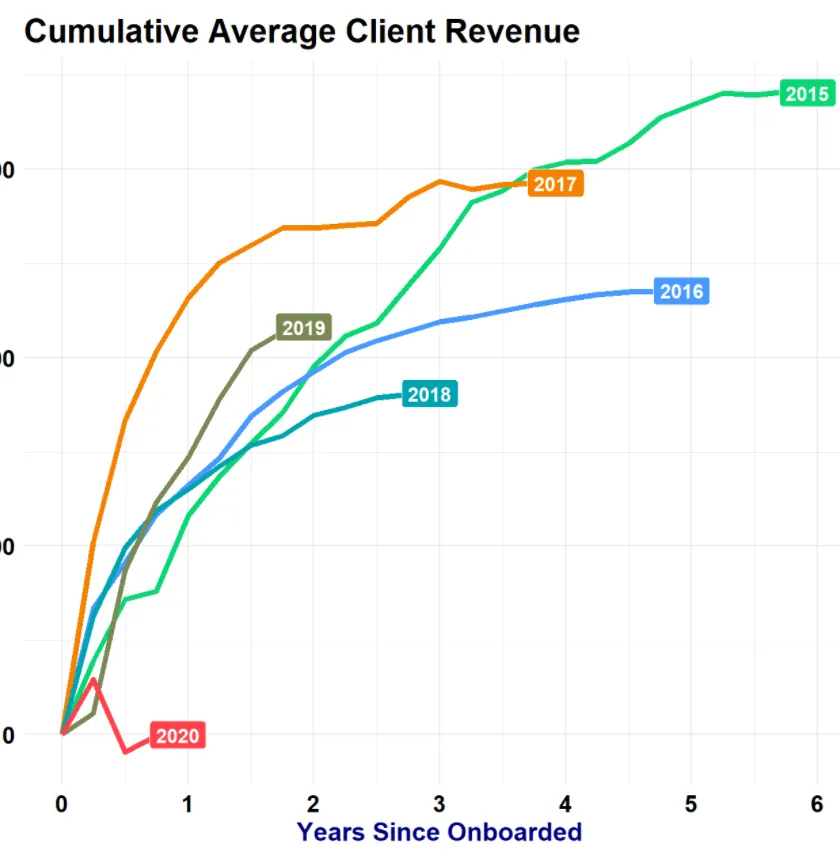
我们在图上看到的年份代表的是“Year Onboarded”而不是“Year”。
谁可以帮我计算一个能够绘制类似于上面的图表的累积平均收入?谢谢
另外,玩具数据集中提供的数据肯定不会给出类似于示例图的东西,但主要思想应该在其中。