我试图优化一些我获得的代码,其中对时间序列(以列表形式给出)进行滑动窗口FFT处理,并将每个结果累加到列表中。原始代码如下:
def calc_old(raw_data):
FFT_old = list()
for i in range(0, len(raw_data), bf.WINDOW_STRIDE_LEN):
if (i + bf.WINDOW_LEN) >= len(raw_data):
# Skip the windows that would extend beyond the end of the data
continue
data_tmp = raw_data[i:i+bf.WINDOW_LEN]
data_tmp -= np.mean(data_tmp)
data_tmp = np.multiply(data_tmp, np.hanning(len(data_tmp)))
fft_data_tmp = np.fft.fft(data_tmp, n=ZERO_PAD_LEN)
fft_data_tmp = abs(fft_data_tmp[:int(len(fft_data_tmp)/2)])**2
FFT_old.append(fft_data_tmp)
新代码如下:
def calc_new(raw_data):
data = np.array(raw_data) # Required as the data is being handed in as a list
f, t, FFT_new = spectrogram(data,
fs=60.0,
window="hann",
nperseg=bf.WINDOW_LEN,
noverlap=bf.WINDOW_OVERLAP,
nfft=bf.ZERO_PAD_LEN,
scaling='spectrum')
总之,旧代码对时间序列进行窗口处理,去除均值,应用Hann窗函数,进行FFT(同时进行零填充,因为
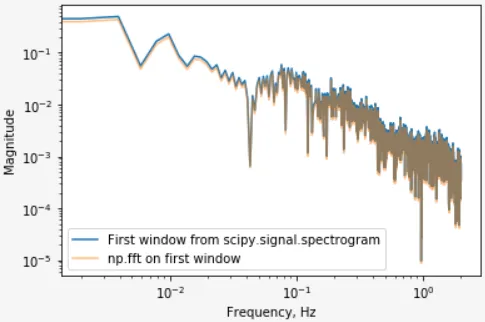
ZERO_PAD_LEN>WINDOW_LEN),然后取实数半部分的绝对值并平方,以生成功率谱(单位为V**2)。然后将窗口移位WINDOW_STRIDE_LEN,并重复该过程,直到窗口延伸到数据末尾。这具有WINDOW_OVERLAP的重叠。据我所知,谱图应该根据给定参数执行相同的操作。但是,每个轴的FFT的结果维度存在1的差异(例如,旧代码为MxN,新代码为(M+1)x(N+1)),每个频率bin中的值相差很大,有时相差几个数量级。
我错在哪里了?