我正在制作两个分类变量和一个数字数据的一系列条形图。我已经有如下内容,但我希望像使用ggplot中的facet_wrap一样按一个分类变量进行细分。我有一个部分有效的示例,但我得到了错误的图表类型(线条而不是条形图),而且我在循环中对数据进行了子集划分,这肯定不是最好的方式。
## first try--plain vanilla
import pandas as pd
import numpy as np
N = 100
## generate toy data
ind = np.random.choice(['a','b','c'], N)
cty = np.random.choice(['x','y','z'], N)
jobs = np.random.randint(low=1,high=250,size=N)
## prep data frame
df_city = pd.DataFrame({'industry':ind,'city':cty,'jobs':jobs})
df_city_grouped = df_city.groupby(['city','industry']).jobs.sum().unstack()
df_city_grouped.plot(kind='bar',stacked=True,figsize=(9, 6))
这将会得到类似于这样的结果:
city industry jobs
0 z b 180
1 z c 121
2 x a 33
3 z a 121
4 z c 236
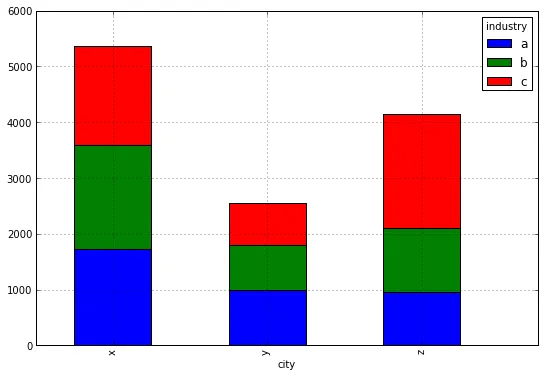
然而,我想看到的是这样的:
(以下内容需要更多上下文信息才能进行准确翻译,请提供更多信息)
## R code
library(plyr)
df_city<-read.csv('/home/aksel/Downloads/mockcity.csv',sep='\t')
## summarize
df_city_grouped <- ddply(df_city, .(city,industry), summarise, jobstot = sum(jobs))
## plot
ggplot(df_city_grouped, aes(x=industry, y=jobstot)) +
geom_bar(stat='identity') +
facet_wrap(~city)
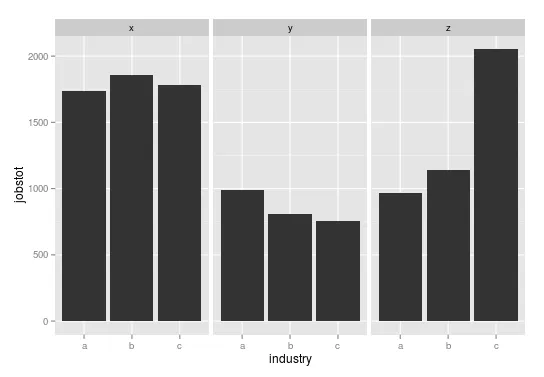
在Matplotlib中最接近的效果大概是这样的:
cols =df_city.city.value_counts().shape[0]
fig, axes = plt.subplots(1, cols, figsize=(8, 8))
for x, city in enumerate(df_city.city.value_counts().index.values):
data = df_city[(df_city['city'] == city)]
data = data.groupby(['industry']).jobs.sum()
axes[x].plot(data)
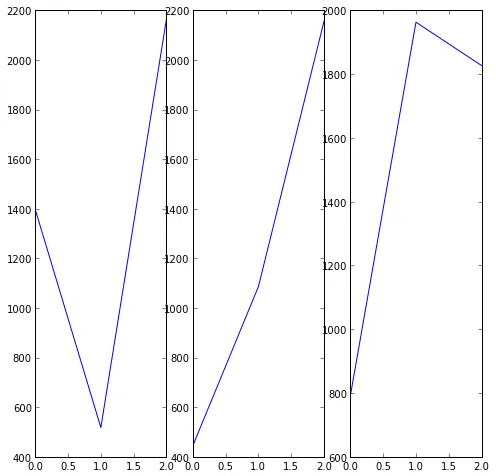
因此有两个问题:
- 我能使用AxesSubplot对象绘制条形图(它们会像这里显示的那样绘制线条),并最终得到类似于facet_wrap示例的东西吗?
- 在生成此类尝试的循环中,我对每个数据进行了子集处理。 我想象不出这是做这种分面的“正确”方式,您认为呢?
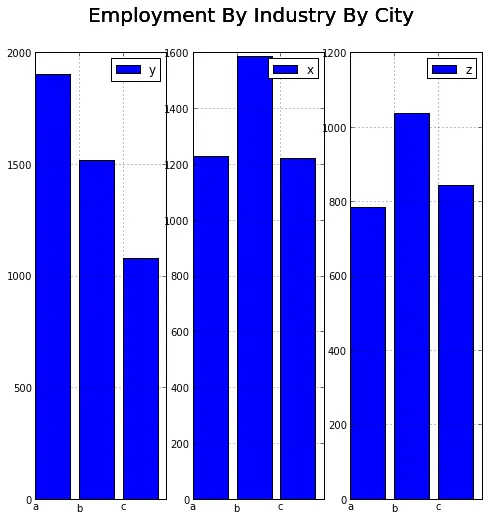
bar呢? - tacaswell