我对统计学和R非常陌生。也许这是一个非常琐碎的问题,但我真的不明白这是如何工作的。
假设我使用 dnorm(5, 0, 2.5)。这是什么意思?
我看到一些资源告诉我,这个函数计算密度曲线上某点的高度。
现在我又读到,在连续分布中,一个数的确切概率为0。那么,我的问题是,如果我可以找出某个值的高度或概率,那么为什么它是0呢?
我知道我混淆了一些概念。但我找不到我错在哪里。如果您能抽出时间帮助我理解这个问题,那将是非常棒的。提前感谢您。
我对统计学和R非常陌生。也许这是一个非常琐碎的问题,但我真的不明白这是如何工作的。
假设我使用 dnorm(5, 0, 2.5)。这是什么意思?
我看到一些资源告诉我,这个函数计算密度曲线上某点的高度。
现在我又读到,在连续分布中,一个数的确切概率为0。那么,我的问题是,如果我可以找出某个值的高度或概率,那么为什么它是0呢?
我知道我混淆了一些概念。但我找不到我错在哪里。如果您能抽出时间帮助我理解这个问题,那将是非常棒的。提前感谢您。
x <- seq(from = -7.5, to = 7.55, by = 0.1)
y <- dnorm(x, 0, 2.5)
这些密度形成的曲线下面积的近似值(我已将其存储为y),乘以它们之间的距离(0.1),接近于1:
> sum(y * 0.1)
[1] 0.9974739
如果您使用微积分进行正确计算,而不是用数字进行近似计算,那么结果将恰好为1。
这有什么用处呢?曲线下部分的累积面积可用于估计变量出现在特定范围内的概率,尽管正如您的某些来源指出的那样,连续变量的任何精确数字的概率技术上都为零。
考虑一下这个图形。阴影空间的面积显示了取自正态分布(平均值为零,标准偏差为2.5)的变量在-7.5到4之间的概率。这导致了许多有用的应用。
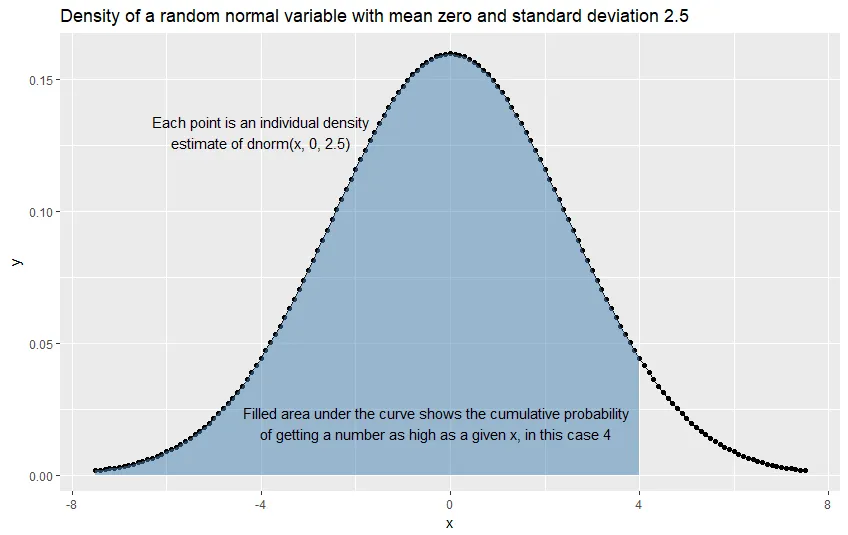
Made with:
library(ggplot2)
d <- data.frame(x, y)
ggplot(d, aes(x = x, y = y)) +
geom_line() +
geom_point() +
geom_ribbon(fill = "steelblue", aes(ymax = y), ymin = 0, alpha = 0.5, data = subset(d, x <= 4)) +
annotate("text", x= -4, y = 0.13, label = "Each point is an individual density\nestimate of dnorm(x, 0, 2.5)") +
annotate("text", x = -.3, y = 0.02, label = "Filled area under the curve shows the cumulative probability\nof getting a number as high as a given x, in this case 4") +
ggtitle("Density of a random normal variable with mean zero and standard deviation 2.5")
dnorm(1.12, mean = 1.0888677, sd = 0.030749282)等于7.771136?dnorm 的输出不应该在 0 和 1 之间吗? - Krantz