我正在使用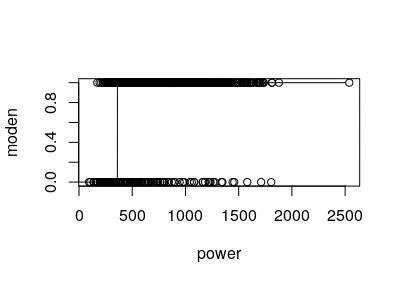 以下是生成该图的代码:
以下是生成该图的代码:
希望能得到帮助。谢谢! 祝好, Marius
geepack进行R语言中的逻辑边际模型估计,使用geeglm()函数。但是我得到了垃圾估计值,它们大约比期望值高16个数量级。然而,p值似乎与预期相似。这意味着响应基本上变成了一个阶梯函数。请参见附图
以下是生成该图的代码:require(geepack)
data = read.csv(url("http://folk.uio.no/mariujon/data.csv"))
fit = geeglm(moden ~ 1 + power, id = defacto, data=data, corstr = "exchangeable", family=binomial)
summary(fit)
plot(moden ~ power, data=data)
x = 0:2500
y = predict(fit, newdata=data.frame(power = x), type="response" )
lines(x,y)
这是回归表格:
Call:
geeglm(formula = moden ~ 1 + power, family = binomial, data = data,
id = defacto, corstr = "exchangeable")
Coefficients:
Estimate Std.err Wald Pr(>|W|)
(Intercept) -7.38e+15 1.47e+15 25.1 5.4e-07 ***
power 2.05e+13 1.60e+12 164.4 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Estimated Scale Parameters:
Estimate Std.err
(Intercept) 1.03e+15 1.65e+37
Correlation: Structure = exchangeable Link = identity
Estimated Correlation Parameters:
Estimate Std.err
alpha 0.196 3.15e+21
Number of clusters: 3 Maximum cluster size: 381
希望能得到帮助。谢谢! 祝好, Marius
MCMCglmm或blme软件包),但它将拟合条件模型而不是边际模型...我不知道如何在GEE框架中实现收缩,或者是否已经有人做过这个。 - Ben Bolker(Intercept)的系数为-0.664,power的系数为0.003。是否有兴趣写出来? - swihart