这个问题已经在以下比赛中发布过:
它的解决方案(O(N 3 )算法)可以在这个页面上找到:“USACO DEC08问题'fence'分析”由Bruce Merry和Jacob Steinhardt。
以下是尝试解释此算法。此外,这里是我在C ++ 11中实现的代码。此代码适用于N< = 250和范围为0 .. 1023的整数坐标。不应有三个点在同一条线上。这里是Python脚本,可生成满足这些要求的测试数据。
简化问题的O(N 2 )算法
简化问题:查找包含给定集合的最左侧点(或如果有多个最左侧点,则此多边形应包含其中最高的点)的最大点子集。
要解决这个问题,我们可以通过有向线段连接每对点,然后(隐式地)将每个线段视为图节点,如下图所示:
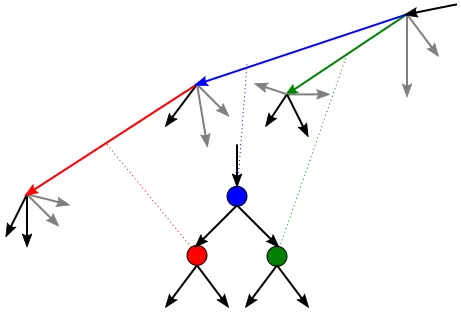
这里父节点和相应的线段具有蓝色。其左子节点(红色)对应的线段从“父”线段的末端开始,它是相对于“父”线段方向做最小可能左转的线段。其右子节点(绿色)对应的线段从“父”线段的起点开始,它也是相对于“父”线段方向做最小可能左转的线段。
以左侧最点结束的任何线段都对应于“叶”节点,即它没有子节点。这种图的构建保证没有循环,换句话说,这个图是一个DAG。
现在要找到最大的凸点子集,只需要在此图中找到最长路径即可。 DAG中的最长路径可以在O(E)的时间内使用动态编程算法找到,其中E是图中的边数。由于每个节点仅具有2个出站边,每个对应于一对点,因此可以在O(N 2 )时间内解决此问题。
如果我们预处理输入数据,将以相同点为起点的有向线段按角度排序,则可以实现这一点。这样可以在图中执行深度优先遍历。我们应该记住从每个处理节点开始的最长路径,以便每个图边最多被访问一次,并且我们有O(E) = O(N^2)时间复杂度算法(暂时忽略预处理时间)。空间要求也是O(N^2),因为我们需要为每对点存储排序的方向,并且记忆化使用每个节点一个值(这也是一对点)。
这是这种动态规划算法的C++实现:
unsigned dpStep(ind_t i_left, ind_t from, ind_t to_ind)
{
ind_t child = sorted[from][to_ind];
while (child < i_left)
child = sorted[from][++to_ind];
if (child == i_left)
return 1;
if (auto v = memorize[from][child])
return v;
const auto x = max(dpStep(i_left, child, lefts[from][child]) + 1,
dpStep(i_left, from, static_cast<ind_t>(to_ind + 1)));
memorize[from][child] = static_cast<ind_t>(x);
return x;
}
输入参数是最左边的点和形成当前线段的一对点(其中线段的起始点直接给出,但结束点是按角度排序的点数组中的索引)。在这段代码片段中,“left”这个词有点过度使用:它既表示最左边的点(
i_left),也表示包含图形左侧子节点的预处理数组(
lefts[][])。
O(N3)算法
通用问题(最左边的点不固定)可以通过以下方式解决:
- 按从左到右的方向对点进行排序。
- 预处理点以获取两个数组:(a)每个点相对于其他点的方向排序,以及(b)使得相对于“父”线段的方向做最小可能左转的线段的末尾在第一个数组中的位置。
- 将每个点用作最左边的点,并使用“简化”的算法找到最长凸多边形。
- 定期从预处理数组中删除“最左边”点左侧的所有点。
- 在步骤3中找到的路径中选择最长的路径。
第4步是可选的。它不会改善O(N3)时间复杂度。但是它通过排除不需要的点略微提高了DP算法的速度。在我的测试中,这可以提高33%的速度。
有几种预处理的替代方法。我们可以计算每个角度(使用atan2)并对它们进行排序,就像Bruce Merry和Jacob Steinhardt在示例代码中所做的那样。这是一种最简单的方法,但是atan2可能太昂贵了,特别是对于较小的点集。
或者,我们可以排除atan2,并对切线而不是角度进行排序,就像我实现的那样。这有点更复杂,但更快。
这两种替代方法都需要O(N2 log N)时间(除非使用某些分布排序)。第三种替代方法是使用众所周知的计算几何方法(排列和对偶性)进行O(N2)预处理。但我认为它对我们的问题没有用处:对于较小的点集,由于大的常数因子,它可能太慢了,因为对于较大的点集,步骤3将大大超过步骤2。而且它要更难实现。
其他一些结果:我尝试实现迭代DP而不是递归;这并没有明显改变速度。我还尝试同时执行两个DP搜索,交错每个搜索的步骤(类似于纤程或在软件中实现的超线程);这可能有所帮助,因为DP主要由具有高延迟的内存访问组成,阻止了CPU吞吐量的充分利用;结果并不是非常令人印象深刻,只有约11%的速度提升,最可能使用真正的超线程会快得多。