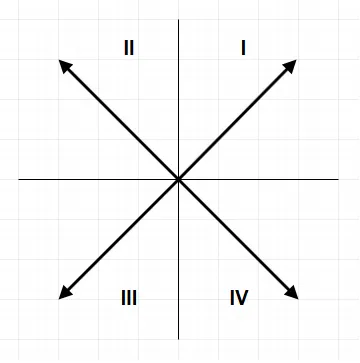
鉴于我们已经排除了 m=i=1 的情况,对于 E[i] 位于第一、二或四象限的情况,必须满足 m>i。如果 E[i] 位于第三象限,则有 m=i,当且仅当 V[i].y > V[i-1].y 为真,或者 m<i。
我们可以将此推理用作二分搜索的基础,在每次迭代中执行以下操作:
if E[i] lies in Quadrant III
if V[i].y > V[i-1].y then m=i
else consider left half
else
consider right half
这里有一些Java代码来说明:
static Point maxY(Point[] v)
{
if(v[1].y < v[0].y && v[v.length-1].y < v[0].y)
{
return v[0];
}
int left = 0;
int right = v.length-1;
Point maxY = null;
while(left <= right)
{
int mid = left + (right-left)/2;
if(v[(mid+1)%v.length].y < v[mid].y && v[(mid+1)%v.length].x < v[mid].x)
{
if(v[mid].y > v[mid-1].y)
{
maxY = v[mid];
break;
}
right = mid - 1;
}
else
{
left = mid + 1;
}
}
return maxY;
}
还有一些简单的测试用例:
public static void main(String[] args)
{
Point[][] tests = {
{new Point(0, 10), new Point(10, 0), new Point(9, 5)},
{new Point(0, 0), new Point(9, 5), new Point(10, 10)},
{new Point(0, 0), new Point(10, 10), new Point(5, 8)},
{new Point(0, 5), new Point(9, 0), new Point(10, 10)},
{new Point(0, 5), new Point(6,0), new Point(10, 6), new Point(5,10)}};
for(Point[] coords : tests)
System.out.println(maxY(coords) + " : " + Arrays.toString(coords));
}
输出:
(0, 10) : [(0, 10), (10, 0), (9, 5)]
(10, 10) : [(0, 0), (9, 5), (10, 10)]
(10, 10) : [(0, 0), (10, 10), (5, 8)]
(10, 10) : [(0, 5), (9, 0), (10, 10)]
(5, 10) : [(0, 5), (6, 0), (10, 6), (5, 10)]
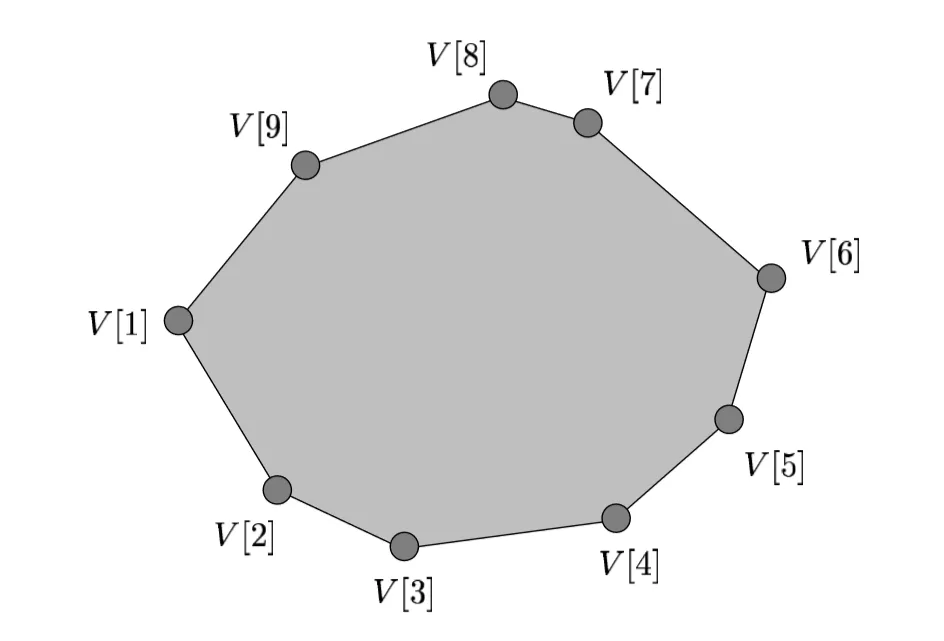 现在,我想找到具有最大y坐标值的顶点。我们都知道朴素的O(n)方法,但是否可能用O(log(n))的时间找到它?
现在,我想找到具有最大y坐标值的顶点。我们都知道朴素的O(n)方法,但是否可能用O(log(n))的时间找到它?