我用Java编写了一个低效但简单的算法,以查看我能够多接近对一组点进行基本聚类的描述。该算法适用于指定为int的(x,y)坐标列表
ps。它还需要其他三个参数:
- 半径(
r):给定一个点,扫描附近点的半径是多少?
- 最大地址数(
maxA):每个簇中的最大地址(点)数是多少?
- 最小地址数(
minA):每个簇中的最小地址数是多少?
将limitA设置为maxA。
主迭代:
初始化空列表possibleSolutions。
外部迭代:对于ps中的每个点p。
初始化空列表pclusters。
定义一个点工作列表wps=copy(ps)。
工作点wp=p。
内部迭代:当wps不为空时。
从wps中删除点wp。确定在距离wp小于r的wps中的所有点wpsInRadius。按照与wp的距离升序排序wpsInRadius。保留wpsInRadius中前min(limitA, sizeOf(wpsInRadius))个点。这些点形成一个新的聚类(点列表)pcluster。将pcluster添加到pclusters中。从wps中删除pcluster中的点。如果wps不为空,则wp=wps[0]并继续内部迭代。
结束内部迭代。
获得聚类列表pclusters。将其添加到possibleSolutions中。
结束外部迭代。
我们对于每个在ps中的p,都有一个possibleSolutions中pclusters列表。每个pclusters都会被加权。如果avgPC是possibleSolutions中每个簇的平均点数(全局),avgCSize是每个pclusters中平均簇数(全局),那么这就是使用这两个变量来确定权重的函数:
private static WeightedPClusters weigh(List<Cluster> pclusters, double avgPC, double avgCSize)
{
double weight = 0;
for (Cluster cluster : pclusters)
{
int ps = cluster.getPoints().size();
double psAvgPC = ps - avgPC;
weight += psAvgPC * psAvgPC / avgCSize;
weight += cluster.getSurface() / ps;
}
return new WeightedPClusters(pclusters, weight);
}
最佳解决方案现在是具有最小权重的
pclusters。只要我们可以找到比先前最佳解决方案(较小的权重)更好的解决方案(限制为
limitA=max(minA,(int)avgPC)),我们就会重复主要迭代。
结束主要迭代。
请注意,对于相同的输入数据,此算法将始终产生相同的结果。列表用于保留顺序,并且没有涉及任何随机性。
为了查看此算法的行为,这是一个由32个点的测试模式生成的结果图像。如果
maxA=minA=16,那么我们会发现2个具有16个地址的聚类。
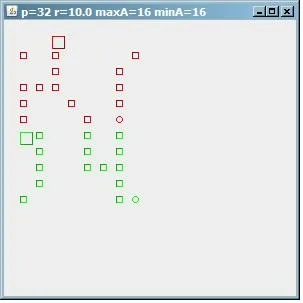 (来源:paperboyalgorithm at sites.google.com)
(来源:paperboyalgorithm at sites.google.com)
接下来,如果我们通过设置
minA=12来减少每个聚类的最小地址数,我们会发现3个点的12/12/8聚类。
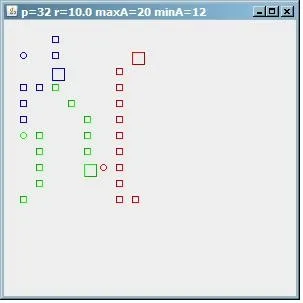
(来源:paperboyalgorithm at sites.google.com)
为了说明该算法远非完美,这里展示了maxA=7的输出结果,但我们得到了6个簇,其中一些很小。因此,在确定参数时仍需要进行太多的猜测。请注意,这里的r只有5。
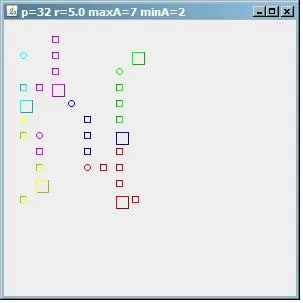
(来源:paperboyalgorithm at sites.google.com)
出于好奇,我尝试对一组更大的随机选择点运行该算法。我添加了下面的图片。
结论?这花费了我半天时间,效率低下,代码看起来很丑陋,而且相对较慢。但它表明在短时间内可以产生一些结果。当然,这只是为了好玩;将其变成实际有用的东西才是困难的部分。

(来源:paperboyalgorithm at sites.google.com)

(来源:paperboyalgorithm at sites.google.com)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}