我想探索大型数组中数据项之间的关系。每个数据项由多维向量表示。首先,我决定使用聚类。我有兴趣找到群集(数据向量组)之间的层次关系。我能够计算我的向量之间的距离。因此,在第一步中,我正在寻找最小生成树。然后,我需要根据生成树中的链接将数据向量分组。但在这一步骤中,我感到困扰 - 如何将不同的向量组合成层次聚类?我使用启发式方法:如果两个向量相连,并且它们之间的距离非常小 - 那就意味着它们在同一个簇中,如果两个向量相连但它们之间的距离大于阈值 - 那就意味着它们在具有共同根簇的不同簇中。
但也许有更好的解决方案吗?
谢谢
P.S. 感谢大家!
实际上,我尝试过k均值和CLOPE的某些变体,但没有得到很好的结果。
因此,现在我知道我的数据集的聚类实际上具有复杂结构(比n球更复杂)。
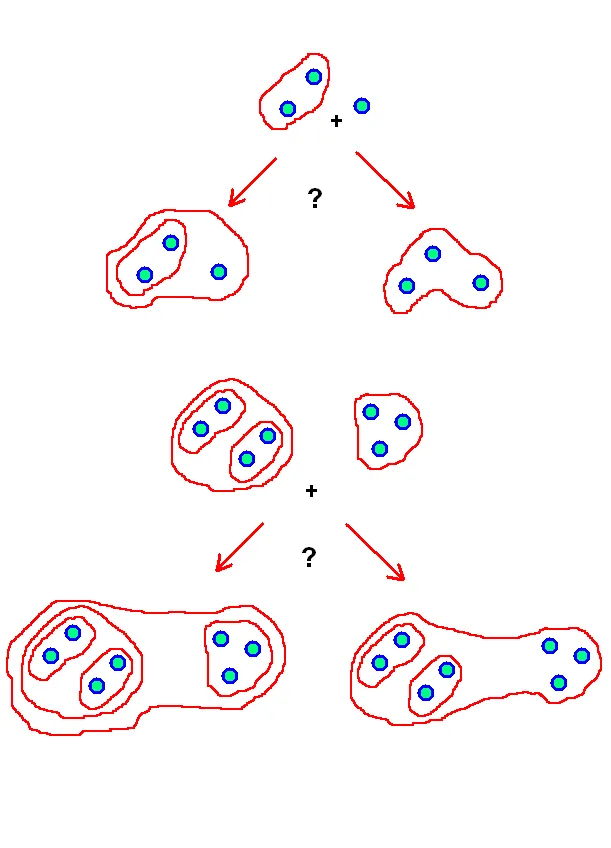
这就是为什么我想使用分层聚类。此外,我猜测聚类看起来像n维连接(如3d或2d链)。因此,我使用单链接策略。 但我感到困扰 - 如何将不同的聚类彼此组合在一起(在哪种情况下我必须创建共同根簇,在哪些情况下我必须将所有子簇组合成一个簇?)。 我使用这样简单的策略:
- 如果群集(或向量)彼此太接近 - 我将它们的内容合并为一个群集(由阈值调节)
- 如果群集(或向量)彼此太远 - 我将创建根群集并将它们放入其中
但是使用这个策略,我得到了非常大的簇树。我试图找到令人满意的阈值。但也许有更好的策略来生成簇树?
这里是一个简单的图片,描述了我的问题: