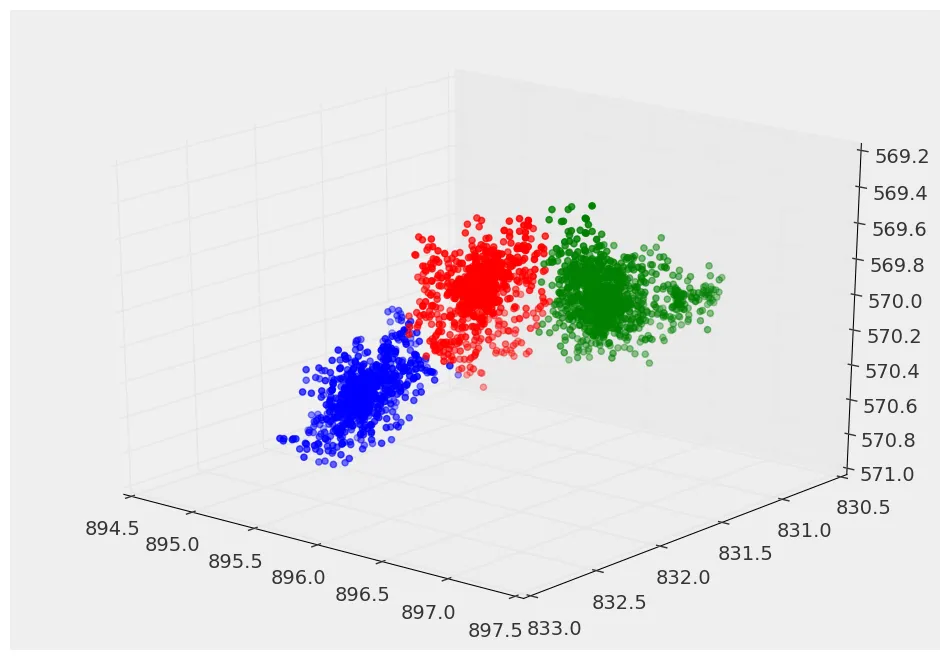
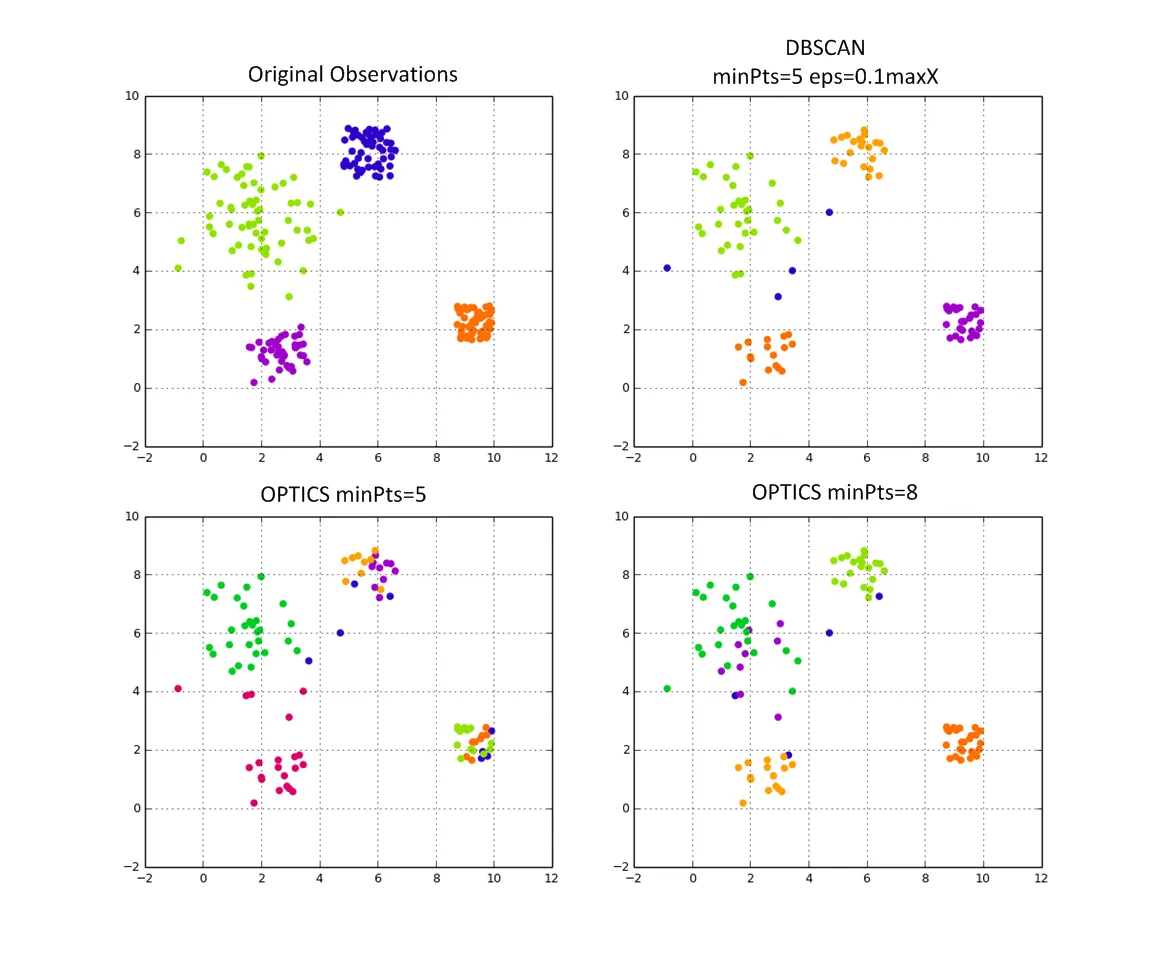
我一直在搜索针对特定问题的聚类算法,使用scipy和sklearn。我需要将N个粒子的种群表征成k个组,其中k不一定已知,此外,没有先验的链接长度(类似于这个问题)。
我已经尝试了kmeans,如果您知道要分多少个簇,则效果很好。我也尝试了dbscan,但除非您告诉它停止(或开始)寻找簇的特征长度尺度,否则其效果不佳。问题是,我可能有成千上万个这些粒子集群,我无法告诉kmeans/dbscan算法他们应该依据什么去进行聚类。
这里有一个dbscan找到的示例:
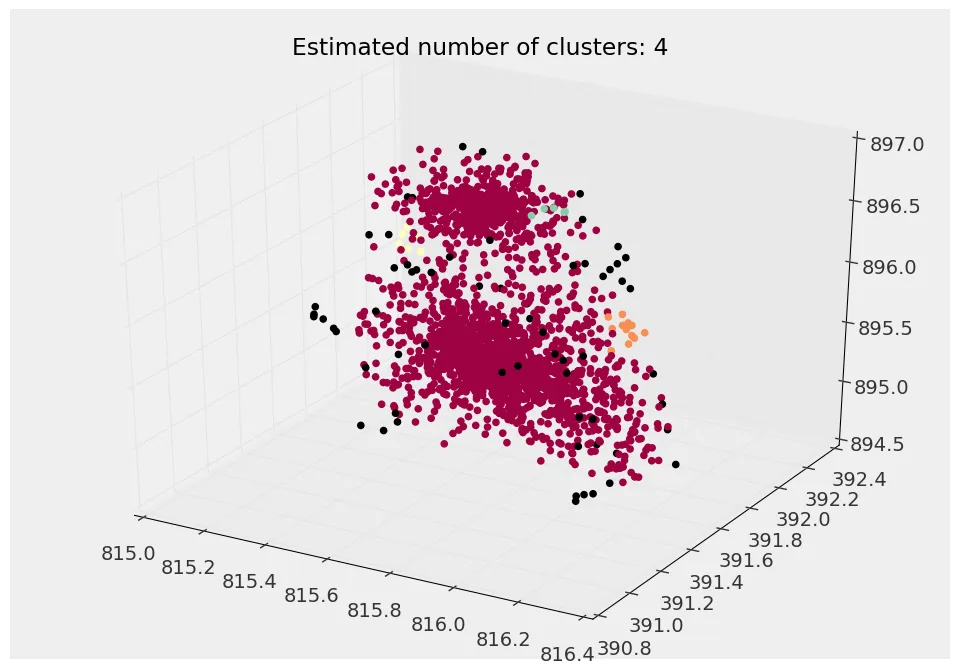
您可以看到这里确实有两个独立的种群,但是,通过调整epsilon因子(相邻集群参数之间的最大距离),我根本无法让它看到这两个粒子集群。
还有其他算法适用于此吗?我正在寻找尽可能少的先验信息-换句话说,我希望算法能够做出关于什么可能构成单独集群的“聪明”决策。