鉴于我已知样本的最大值、最小值和平均值(但无法访问样本本身),我想编写一个通用函数来生成具有相同特征的样本。从这个答案中可以了解到,这并不是一项简单的任务,因为有许多分布可以具有相同的特征。
max, min, average = [411, 1, 20.98]
我正在尝试使用scipy.norm,但是不成功。我似乎无法理解我是否可以传递上述参数,还是它们只是从已生成的函数返回的值。由于我对Python统计学很陌生,因此这可能是一个相当容易解决的问题。
鉴于我已知样本的最大值、最小值和平均值(但无法访问样本本身),我想编写一个通用函数来生成具有相同特征的样本。从这个答案中可以了解到,这并不是一项简单的任务,因为有许多分布可以具有相同的特征。
max, min, average = [411, 1, 20.98]
我正在尝试使用scipy.norm,但是不成功。我似乎无法理解我是否可以传递上述参数,还是它们只是从已生成的函数返回的值。由于我对Python统计学很陌生,因此这可能是一个相当容易解决的问题。
import numpy as np
import matplotlib.pyplot as plt
h = plt.hist(np.random.triangular(-3, 0, 8, 100000), bins=200,
density=True)
plt.show()
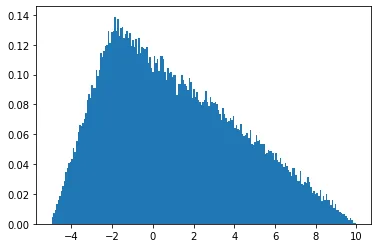
a = np.random.triangular(-3, 0, 8, 100)
print(min(a))
print(max(a))这些函数中设置的限制仅表示允许的限制,而不是保证的限制。 - StephanT如此处所述:
存在无数可能的分布与这些样本量相一致。
但您可以引入其他假设来找到一些解决方案:
您可以将其视为优化问题:查找具有最佳拟合度(以指定的最小/最大/平均统计数据为准)的分布及其参数。 伪代码解决方案如下:
candidates = []
for distribution in distributions:
best_parameters, score = find_best_parameters(distribution, target_statistics)
candidates.append((distribution, best_parameters, score))
best_distribution = sorted(candidates, key=lambda x: x[2])
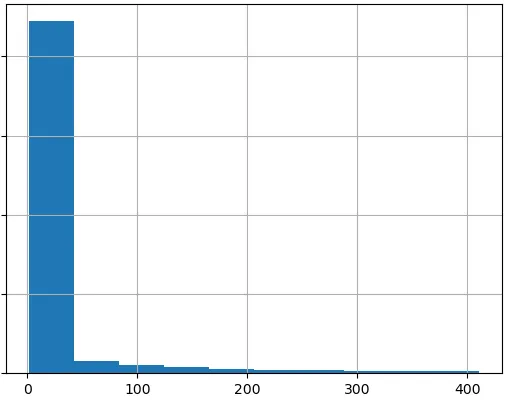
s = stats.powerlaw(a=5.0909e-2, loc=1.00382, scale=4.122466e+2)
sample = s.rvs(size=100_000)
print(np.max(sample), np.min(sample), np.mean(sample))
最大值/最小值/平均值:
411.02946481216634 0.994030016 20.943683603008324
完整代码:
import numpy as np
from scipy import stats
import cma
from matplotlib import pyplot as plt
distributions_and_bounds = [
(stats.cauchy, {'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.chi2, {'loc': [0, 1000], 'scale': [0, None]}),
(stats.expon, {'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.exponpow, {'b': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.gamma, {'a': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.lognorm, {'s': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.norm, {'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.powerlaw, {'a': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.rayleigh, {'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.uniform, {'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.alpha, {'a': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.anglit, {'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.arcsine, {'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.burr, {'c': [0, None], 'd': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.argus, {'chi': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
(stats.beta, {'a': [0, None], 'b': [0, None], 'loc': [-1000, 1000], 'scale': [0, None]}),
]
target_params = np.array([411, 1, 20.98])
candidates = []
for distribution, bounds in distributions_and_bounds:
def objective(params):
sample = distribution(*params).rvs(size=1_000)
pred_params = np.array([np.max(sample), np.min(sample), np.mean(sample)])
mse = (np.abs(target_params - pred_params) ** 2).mean()
return mse
x0 = np.ones(len(bounds))
lower_bounds = [bound[0] for bound in bounds.values()]
upper_bounds = [bound[1] for bound in bounds.values()]
best_params, es = cma.fmin2(objective, x0, 1, {'bounds': [lower_bounds, upper_bounds]}, restarts=4)
score = objective(best_params)
candidates.append((score, distribution, best_params))
best_distribution = list(sorted(candidates, key=lambda x: x[0]))[0]
print(best_distribution)
快速编辑并加以阐述(我后来意识到):您可以在任何分布上应用平衡技巧。
许多提议的解决方案痛点在于,使用浮点数命中最小值、最大值和平均值的确切值的机会基本为零。因此,需要手动添加最小值和最大值,但是添加值会影响生成的分布。
一种朴素的方法是生成分布,添加最小值和最大值,并平衡它们以达到平均值:
前三个步骤确保边界条件(最小值、最大值)不会破坏平均值。步骤4-5创建一些保证具有所需平均值的确切数据,并将其落在最小值和最大值之间。步骤6将数据组合成所需结果。
import math
import numpy as np
MAX, MIN, AVERAGE = [411, 3, 20.98]
data = [3, 411]
left = AVERAGE - MIN
right = MAX - AVERAGE
ratio = max(left, right)/min(left,right)
n = math.ceil(ratio) - 1
dx = math.ceil(ratio) - ratio # this checks overcompensation due to working with integer numbers
data = data + [MIN]*(n) + [AVERAGE + left*dx] # the second part compensates the overcompensation again :)
print(np.mean(data))
print(min(data))
print(max(data))
N = 1000
width = min(MAX-AVERAGE, AVERAGE-MIN)
print(width)
dist = np.random.normal(AVERAGE, width/3, N)
delta1 = np.mean(dist) - AVERAGE
dist = [x for x in dist if x > (MIN + delta1) and x < (MAX - delta1)]
delta2 = np.mean(dist) - AVERAGE
dist = [x - delta2 for x in dist]
full = data + dist
print(np.mean(full))
print(min(full))
print(max(full))
让我们尝试以下函数:
import numpy as np
import random
def re_sample(min_v, max_v, mean_v, size):
"""
Parameters
----------
min_v : Minimum value of the original population
max_v : Maximum value of the original population
mean_v : Mean value of the original population
size : Number of observation we want to generate
Returns
-------
sample : List of simulated values
"""
s_min_to_mean=int(((max_v-mean_v)/(max_v-min_v))*size)
sample_1=[random.uniform(min_v, mean_v) for i in range(s_min_to_mean)]
sample_2=[random.uniform(mean_v, max_v) for i in range(size-s_min_to_mean)]
sample=sample_1+sample_2
sample=random.sample(sample, len(sample))
sample=[round(x, 2) for x in sample]
return sample
当我按照以下方式测试这个函数时:
sample = re_sample(1, 411, 20.98, 200)
print(np.mean(sample))
print(np.min(sample))
print(np.max(sample))
print(type(sample))
print(len(sample))
print(sample)
>>> 19.8997
>>> 1.0
>>> 307.8
>>> <class 'list'>
>>> 200
>>> [20.55, 7.87, 3.48, 5.23, 18.54, 268.06, 1.71,....