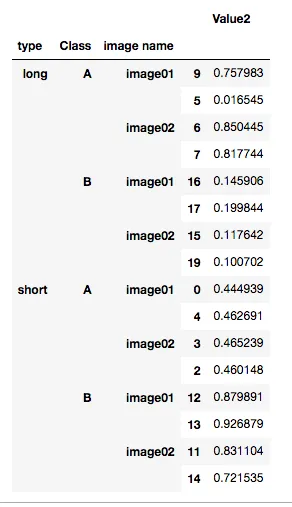
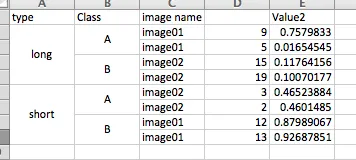
据我所知,问题在于您不想按图像名称列进行分组,但如果不将该列包含在groupby中,则会丢失此列。
您可以首先创建groupby对象。
gb = df.groupby(['type', 'Class'])
现在你可以使用列表推导式对分组块进行迭代。
blocks = [data.sample(n=1) for _,data in gb]
现在,您可以连接这些块来重构您随机抽样的数据框。
pd.concat(blocks)
输出
Class Value2 image name type
7 A 0.817744 image02 long
17 B 0.199844 image01 long
4 A 0.462691 image01 short
11 B 0.831104 image02 short
或者
您可以修改代码并将列image name添加到groupby中,像这样:
df.groupby(['type', 'Class'])[['Value2','image name']].apply(lambda s: s.sample(min(len(s),2)))
Value2 image name
type Class
long A 8 0.777962 image01
9 0.757983 image01
B 19 0.100702 image02
15 0.117642 image02
short A 3 0.465239 image02
2 0.460148 image02
B 10 0.934829 image02
11 0.831104 image02
编辑:保持每组相同的图像
我不确定是否可以避免使用迭代过程来解决这个问题。您可以只循环遍历groupby块,筛选组并选择一个随机图像并保持每组相同名称,然后从剩余的图像中随机抽样,如下:
import random
gb = df.groupby(['Class','type'])
ls = []
for index,frame in gb:
ls.append(frame[frame['image name'] == random.choice(frame['image name'].unique())].sample(n=2))
pd.concat(ls)
输出
Class Value2 image name type
6 A 0.850445 image02 long
7 A 0.817744 image02 long
4 A 0.462691 image01 short
0 A 0.444939 image01 short
19 B 0.100702 image02 long
15 B 0.117642 image02 long
10 B 0.934829 image02 short
14 B 0.721535 image02 short