我想按组计算值的变化。
这是我拥有的 Python Pandas 数据框 df:
我想计算出A组的值正在上升,B组的值正在下降,而C组的值没有变化。
我不确定如何处理,因为在A组中,值最初会下降,然后再上升。所以我应该看平均变化还是最近的变化?
我应该使用pct_change吗?http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.pct_change.html 我不确定如何指定时间范围。
如果我也能将其可视化,那就太好了。非常感谢您的任何建议或提示!谢谢。
这是我拥有的 Python Pandas 数据框 df:
Group | Date | Value
A 01-02-2016 16
A 01-03-2016 15
A 01-04-2016 14
A 01-05-2016 17
A 01-06-2016 19
A 01-07-2016 20
B 01-02-2016 16
B 01-03-2016 13
B 01-04-2016 13
C 01-02-2016 16
C 01-03-2016 16
我想计算出A组的值正在上升,B组的值正在下降,而C组的值没有变化。
我不确定如何处理,因为在A组中,值最初会下降,然后再上升。所以我应该看平均变化还是最近的变化?
我应该使用pct_change吗?http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.pct_change.html 我不确定如何指定时间范围。
df.groupby.pct_change
如果我也能将其可视化,那就太好了。非常感谢您的任何建议或提示!谢谢。
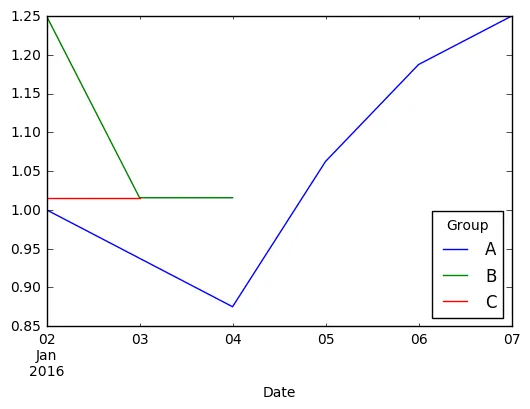
.describe()得到标准差。我正在寻找平均变化,所以代码应该是这样的:df_group = df.groupby('Group') df_new = df_group['Value'].pct_change().mean()。 - jeangeljdf_group.Value.apply(lambda df: df.pct_change().mean())但是pct_mean()的结果会在零附近振荡,可能会减弱您对变化程度的观察。使用df_group.Value.apply(lambda df: df.pct_change().abs().mean())可能更好。 - piRSquared