这是我的问题的续篇。比较两个pandas数据框行的最快方法?
我有两个数据框 A 和 B:
A 是1000行x 500列,填充了二进制值,指示存在或不存在。
举个简单的例子:
但是当我这样做时,
A 是1000行x 500列,填充了二进制值,指示存在或不存在。
举个简单的例子:
A B C D E
0 0 0 0 1 0
1 1 1 1 1 0
2 1 0 0 1 1
3 0 1 1 1 0
B 是一个1024行x10列的矩阵,是从0到1023的二进制形式的完整迭代。
示例:
0 1 2
0 0 0 0
1 0 0 1
2 0 1 0
3 0 1 1
4 1 0 0
5 1 0 1
6 1 1 0
7 1 1 1
我正在尝试找出A中特定10列的哪些行与B中的每一行对应。
可以保证A [My_Columns_List]的每一行都会在B中的某个地方,但并非B的每一行都能与A [My_Columns_List]中的一行匹配。
例如,我想展示A的列[B,D,E]:
A的行[1,3]与B的行[6]对应,
A的行[0]与B的行[2]对应,
A的行[2]与B的行[3]对应。
我已经尝试使用:
pd.merge(B.reset_index(), A.reset_index(),
left_on = B.columns.tolist(),
right_on =A.columns[My_Columns_List].tolist(),
suffixes = ('_B','_A')))
这个方法是可行的,但我希望它能更快:
S = 2**np.arange(10)
A_ID = np.dot(A[My_Columns_List],S)
B_ID = np.dot(B,S)
out_row_idx = np.where(np.in1d(A_ID,B_ID))[0]
但是当我这样做时,
out_row_idx返回一个包含所有A索引的数组,这并没有告诉我任何信息。我认为这种方法会更快,但我不知道为什么它返回从0到999的数组。欢迎任何意见!同时,感谢@jezrael和@Divakar提供的这些方法。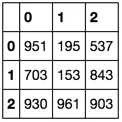
A,B,当数据框A也包含列A,B,C...时,请将数据框命名为df1,df2或dfa,dfb。此外,在 Python 中,我们使用 PEP-8 命名约定来命名变量,因此不要使用A_ID,而是使用a_id或者更好的id_a。 - smci