我希望能够逐行比较两个表格,并仅保留相似的匹配项。
在此表格中进行转换:
import pandas as pd
df = pd.DataFrame.from_items([('a', [0,1,1,0]), ('b', [0,0,1,1]),('c',[1,0,0,1]), ('d',[1,0,1,0])], orient='index', columns=['A', 'B', 'C', 'D'])
df
A B C D
a 0 1 1 0
b 0 0 1 1
c 1 0 0 1
d 1 0 1 0
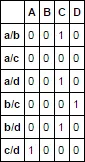
在此表格中进行转换:
A B C D
a/b 0 0 1 0
a/c 0 0 0 0
a/d 0 0 1 0
a/d 0 0 0 0
b/c 0 0 0 1
b/d 0 0 1 0
c/d 1 0 0 0