> summary(mydata)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0 93 107 110 125 197
> range=1.5*(125-93)
> upper_whisker=125+range
> lower_whisker=93-range
> upper_whisker
[1] 173
> lower_whisker
[1] 45
> boxplot(mydata)$stats
[,1]
[1,] 56 #Lower whisker by boxplot
[2,] 93
[3,] 107
[4,] 125
[5,] 173
我试图查找计算哪些值在之后和之前被视为异常值的公式。
Above =>3rd Qu +(3rd Qu - 1st Qu)*1.5
Below =>1st Qu -(3rd Qu - 1st Qu)*1.5
由于某种原因,它们似乎与R中的箱线图函数返回的统计数据不匹配。我有一种感觉这里有什么愚蠢的事情。
它们被计算得不同吗?或者我从boxplot读取了错误的答案?
编辑:
我使用了https://www.kaggle.com/uciml/pima-indians-diabetes-database并运行了
mydata=raw$Glucose[raw$Outcome==0]
EDIT2:
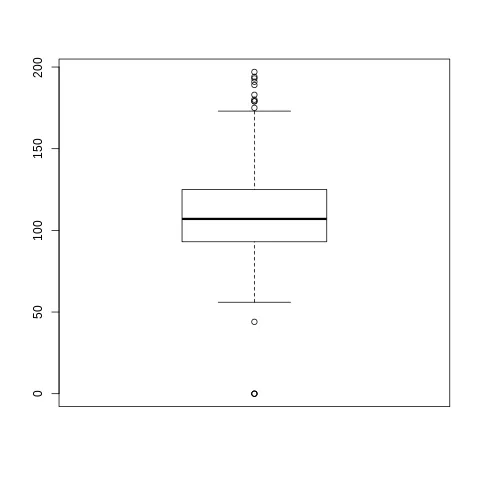
我想如果
#max(min(x), Q1 - (IQR(x)*1.5)) #lower whisker
如果返回min(x),则不应该有任何异常值,而min(mydata)为0。
编辑3: Quantile的清晰视图。
quantile(mydata)
0% 25% 50% 75% 100%
0 93 107 125 197
编辑4:按要求添加了vector
c(85L, 89L, 116L, 115L, 110L, 139L, 103L, 126L, 99L, 97L, 145L,
117L, 109L, 88L, 92L, 122L, 103L, 138L, 180L, 133L, 106L, 159L,
146L, 71L, 105L, 103L, 101L, 88L, 150L, 73L, 100L, 146L, 105L,
84L, 44L, 141L, 99L, 109L, 95L, 146L, 139L, 129L, 79L, 0L, 62L,
95L, 112L, 113L, 74L, 83L, 101L, 110L, 106L, 100L, 107L, 80L,
123L, 81L, 142L, 144L, 92L, 71L, 93L, 151L, 125L, 81L, 85L, 126L,
96L, 144L, 83L, 89L, 76L, 78L, 97L, 99L, 111L, 107L, 132L, 120L,
118L, 84L, 96L, 125L, 100L, 93L, 129L, 105L, 128L, 106L, 108L,
154L, 102L, 57L, 106L, 147L, 90L, 136L, 114L, 153L, 99L, 109L,
88L, 151L, 102L, 114L, 100L, 148L, 120L, 110L, 111L, 87L, 79L,
75L, 85L, 143L, 87L, 119L, 0L, 73L, 141L, 111L, 123L, 85L, 105L,
113L, 138L, 108L, 99L, 103L, 111L, 96L, 81L, 147L, 179L, 125L,
119L, 142L, 100L, 87L, 101L, 197L, 117L, 79L, 122L, 74L, 104L,
91L, 91L, 146L, 122L, 165L, 124L, 111L, 106L, 129L, 90L, 86L,
111L, 114L, 193L, 191L, 95L, 142L, 96L, 128L, 102L, 108L, 122L,
71L, 106L, 100L, 104L, 114L, 108L, 129L, 133L, 136L, 155L, 96L,
108L, 78L, 161L, 151L, 126L, 112L, 77L, 150L, 120L, 137L, 80L,
106L, 113L, 112L, 99L, 115L, 129L, 112L, 157L, 179L, 105L, 118L,
87L, 106L, 95L, 165L, 117L, 130L, 95L, 0L, 122L, 95L, 126L, 139L,
116L, 99L, 92L, 137L, 61L, 90L, 90L, 88L, 158L, 103L, 147L, 99L,
101L, 81L, 118L, 84L, 105L, 122L, 98L, 87L, 93L, 107L, 105L,
109L, 90L, 125L, 119L, 100L, 100L, 131L, 116L, 127L, 96L, 82L,
137L, 72L, 123L, 101L, 102L, 112L, 143L, 143L, 97L, 83L, 119L,
94L, 102L, 115L, 94L, 135L, 99L, 89L, 80L, 139L, 90L, 140L, 147L,
97L, 107L, 83L, 117L, 100L, 95L, 120L, 82L, 91L, 119L, 100L,
135L, 86L, 134L, 120L, 71L, 74L, 88L, 115L, 124L, 74L, 97L, 154L,
144L, 137L, 119L, 136L, 114L, 137L, 114L, 126L, 132L, 123L, 85L,
84L, 139L, 173L, 99L, 194L, 83L, 89L, 99L, 80L, 166L, 110L, 81L,
154L, 117L, 84L, 94L, 96L, 75L, 130L, 84L, 120L, 139L, 91L, 91L,
99L, 125L, 76L, 129L, 68L, 124L, 114L, 125L, 87L, 97L, 116L,
117L, 111L, 122L, 107L, 86L, 91L, 77L, 105L, 57L, 127L, 84L,
88L, 131L, 164L, 189L, 116L, 84L, 114L, 88L, 84L, 124L, 97L,
110L, 103L, 85L, 87L, 99L, 91L, 95L, 99L, 92L, 154L, 78L, 130L,
111L, 98L, 143L, 119L, 108L, 133L, 109L, 121L, 100L, 93L, 103L,
73L, 112L, 82L, 123L, 67L, 89L, 109L, 108L, 96L, 124L, 124L,
92L, 152L, 111L, 106L, 105L, 106L, 117L, 68L, 112L, 92L, 183L,
94L, 108L, 90L, 125L, 132L, 128L, 94L, 102L, 111L, 128L, 92L,
104L, 94L, 100L, 102L, 128L, 90L, 103L, 157L, 107L, 91L, 117L,
123L, 120L, 106L, 101L, 120L, 127L, 162L, 112L, 98L, 154L, 165L,
99L, 68L, 123L, 91L, 93L, 101L, 56L, 95L, 136L, 129L, 130L, 107L,
140L, 107L, 121L, 90L, 99L, 127L, 118L, 122L, 129L, 110L, 80L,
127L, 158L, 126L, 134L, 102L, 94L, 108L, 83L, 114L, 117L, 111L,
112L, 116L, 141L, 175L, 92L, 106L, 105L, 95L, 126L, 65L, 99L,
102L, 109L, 153L, 100L, 81L, 121L, 108L, 137L, 106L, 88L, 89L,
101L, 122L, 121L, 93L)
mydata中排除0和44时才能得到min=56,即min(mydata[!mydata %in% c(0, 44)])。这样就可以得到正确的结果。为什么会发生这种情况,目前我还不清楚。 - RLave