我在使用Assimp渲染OpenGL时遇到了性能问题。场景包含367727个三角形,其中298084个是国际象棋模型。我认为问题不在着色器上,因为:
128x128窗口:44(43.7657)FPS,22.849毫秒
256x256窗口:42(40.9563)FPS,24.4162毫秒
512x512窗口:35(34.8007)FPS,28.7351毫秒
1024x1024窗口:22(21.084)FPS,47.4293毫秒
但如果我不绘制棋子,则在1366x763窗口中:55(54.8424)FPS,18.2341毫秒
此外,改变阴影贴图的分辨率对FPS的影响不大。
在场景中有两个点光源,每次绘制此模型时每个通道的FPS损失约为10 FPS(从23到55)。也就是说,我在哪里绘制这个模型没有任何区别:在深度图中还是在“颜色纹理”中。损失量大致相同。我使用以下参数加载模型:
128x128窗口:44(43.7657)FPS,22.849毫秒
256x256窗口:42(40.9563)FPS,24.4162毫秒
512x512窗口:35(34.8007)FPS,28.7351毫秒
1024x1024窗口:22(21.084)FPS,47.4293毫秒
但如果我不绘制棋子,则在1366x763窗口中:55(54.8424)FPS,18.2341毫秒
此外,改变阴影贴图的分辨率对FPS的影响不大。
在场景中有两个点光源,每次绘制此模型时每个通道的FPS损失约为10 FPS(从23到55)。也就是说,我在哪里绘制这个模型没有任何区别:在深度图中还是在“颜色纹理”中。损失量大致相同。我使用以下参数加载模型:
aiProcess_Triangulate | aiProcess_CalcTangentSpace | aiProcess_JoinIdenticalVertices并进行渲染。inline void pointer(GLint location, int count, GLuint buffer) {
glBindBuffer(GL_ARRAY_BUFFER, buffer);
glVertexAttribPointer(
location, // attribute location
count, // count (1, 2, 3 or 4)
GL_FLOAT, // type
GL_FALSE, // is normalized?
0, // step
nullptr // offset
);
}
inline void pointerui(GLint location, int count, GLuint buffer) {
glBindBuffer(GL_ARRAY_BUFFER, buffer);
glVertexAttribIPointer(
location, // attribute location
count, // count (1, 2, 3 or 4)
GL_UNSIGNED_INT, // type
0, // step
nullptr // offset
);
}
...
pointer(cs.inPosition, 3, model.shape->meshes[i].getVerticesBuffer());
pointer(cs.inNormal, 3, model.shape->meshes[i].getNormalsBuffer());
pointer(cs.inTangent, 3, model.shape->meshes[i].getTangentsBuffer());
pointer(cs.inBitangent, 3, model.shape->meshes[i].getBitangentsBuffer());
pointer(cs.inTexCoord, 2, model.shape->meshes[i].getTexCoordsBuffer());
if (model.shape->bonesPerVertex != 0) {
pointer(cs.inBoneWeights, 4, model.shape->meshes[i].getBoneWeightsBuffer());
pointerui(cs.inBoneIds, 4, model.shape->meshes[i].getBoneIdsBuffer());
}
modelMatrix = &model.transformation;
updateMatrices();
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, model.shape->meshes[i].getIndicesBuffer());
glDrawElements(GL_TRIANGLES, model.shape->meshes[i].indices.size(), GL_UNSIGNED_INT, nullptr)
以下是场景本身:
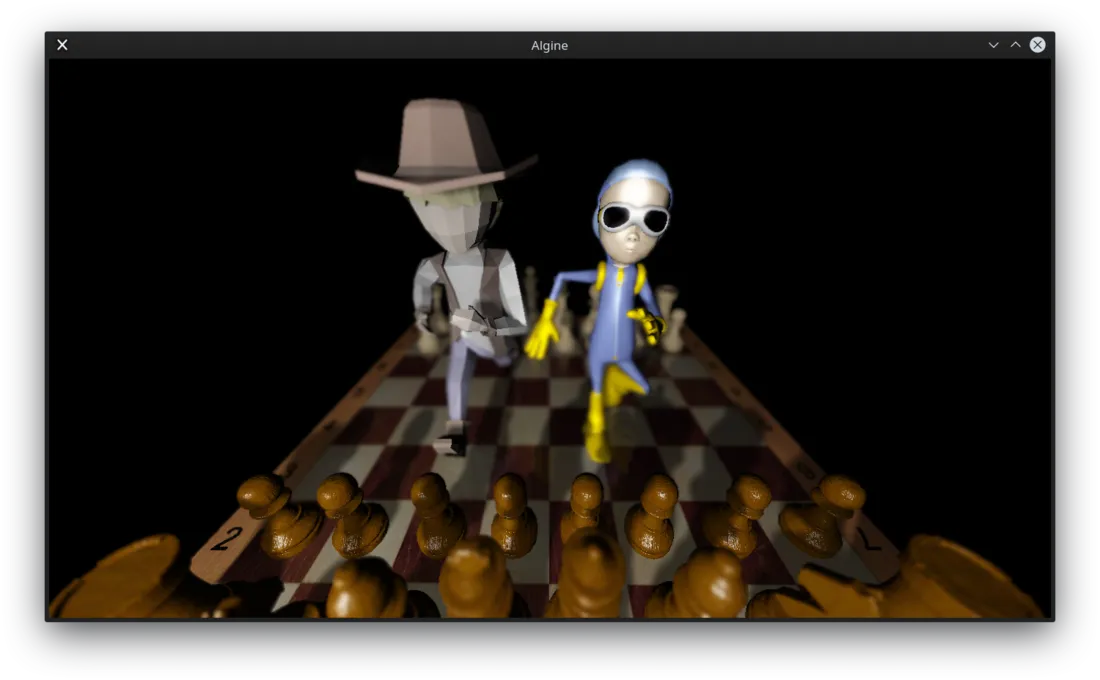
编辑:vertex_shader.glsl, fragment_shader.glsl
非常抱歉片段着色器很难阅读,我还没有完全完成它的工作
我的GPU是NVGF 920mx
编辑:这里是capture来自renderdoc
for 20 do texture lookup可能是罪魁祸首,但需要进行测量才能确定。注意:textureCubeShadow采样器专门用于阴影映射,所以我相信你应该使用它。不过我个人不太熟悉它。 - Andreas