我有一个CSV文件,其中包含我感兴趣的每个(Java GC)事件的行。该对象由亚秒级时间戳(非等距)和一些变量组成。对象如下:
gcdata <- read.table("http://bernd.eckenfels.net/view/gc1001.ygc.csv",header=TRUE,sep=",", dec=".")
start = as.POSIXct(strptime("2012-01-01 00:00:00", format="%Y-%m-%d %H:%M:%S"))
gcdata.date = gcdata$Timestamp + start
gcdata = gcdata[,2:7] # remove old date col
gcdata=data.frame(date=gcdata.date,gcdata)
str(gcdata)
结果
'data.frame': 2997 obs. of 7 variables:
$ date : POSIXct, format: "2012-01-01 00:00:06" "2012-01-01 00:00:06" "2012-01-01 00:00:18" ...
$ Distance.s. : num 0 0.165 11.289 9.029 11.161 ...
$ YGUsedBefore.K.: int 1610619 20140726 20148325 20213304 20310849 20404772 20561918 21115577 21479211 21544930 ...
$ YGUsedAfter.K. : int 7990 15589 80568 178113 272036 429182 982841 1346475 1412181 1355412 ...
$ Promoted.K. : int 0 0 0 0 8226 937 65429 71166 62548 143638 ...
$ YGCapacity.K. : int 22649280 22649280 22649280 22649280 22649280 22649280 22649280 22649280 22649280 22649280 ...
$ Pause.s. : num 0.0379 0.022 0.0287 0.0509 0.109 ...
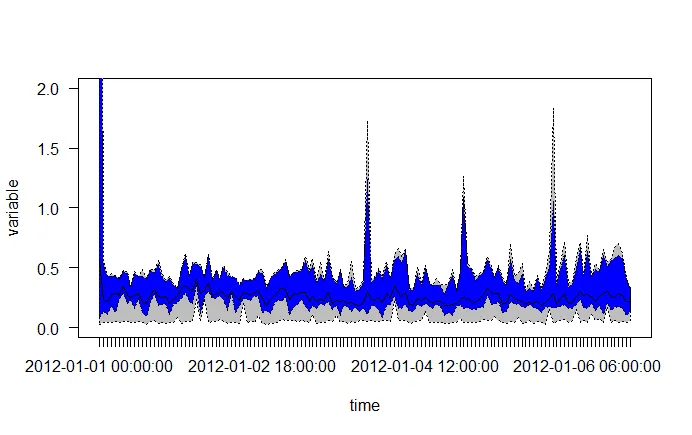
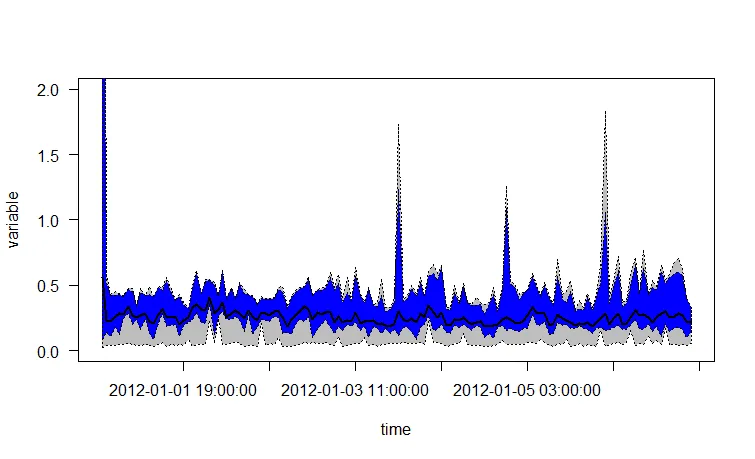
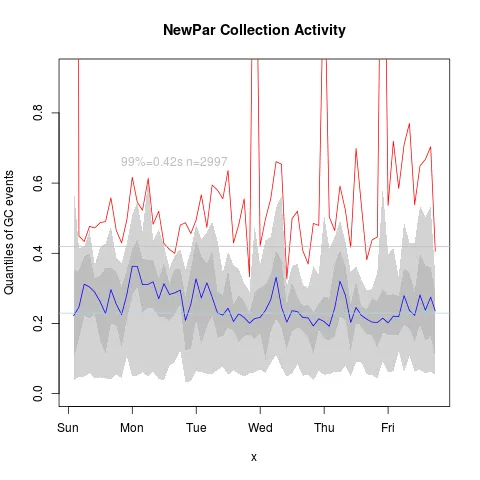
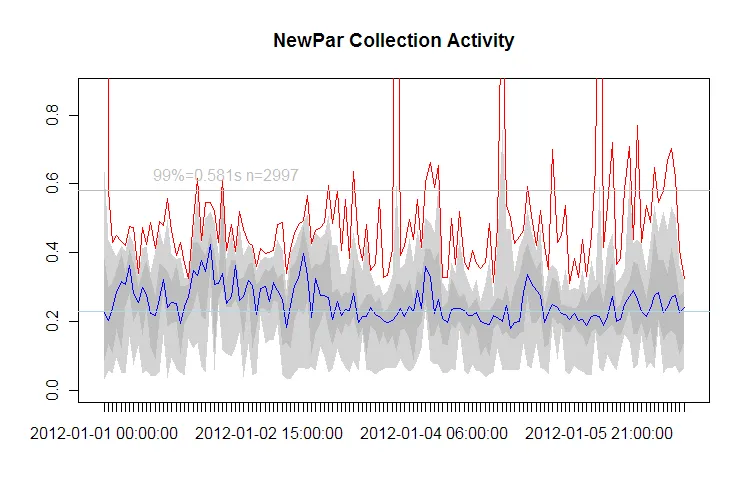
在这种情况下,我关心暂停时间(以秒为单位)。我想绘制一个图表,它将显示每个(挂钟)小时的平均值作为线条,2%和98%作为灰色走廊以及每小时内的最大值作为红线。
我已经做了一些工作,但使用q98函数很丑陋,使用多行语句似乎是浪费的,并且我不知道如何在q02和q98之间实现灰色区域。
q02 <- function(x, ...) { x <- quantile(x,probs=c(0.2)) }
q98 <- function(x, ...) { x <- quantile(x,probs=c(0.98)) }
hours = droplevels(cut(gcdata$date, breaks="hours")) # can I have 2 hours?
plot(aggregate(gcdata$Pause.s. ~ hours, data=gcdata, FUN=max),ylim=c(0,2), col="red", ylab="Pause(s)", xlab="Days") # Is always black?
lines(aggregate(gcdata$Pause.s. ~ hours, data=gcdata, FUN=q98),ylim=c(0,2), col="green")
lines(aggregate(gcdata$Pause.s. ~ hours, data=gcdata, FUN=q02),ylim=c(0,2), col="green")
lines(aggregate(gcdata$Pause.s. ~ hours, data=gcdata, FUN=mean),ylim=c(0,2), col="blue")
现在,这将导致图表具有黑点作为最大值、蓝线作为每小时平均值以及下限和上限 0.2 + 0.98 绿线。我认为更好的阅读体验是使用灰色走廊,可能是虚线的最大值(红色)线,并以某种方式固定轴标签。
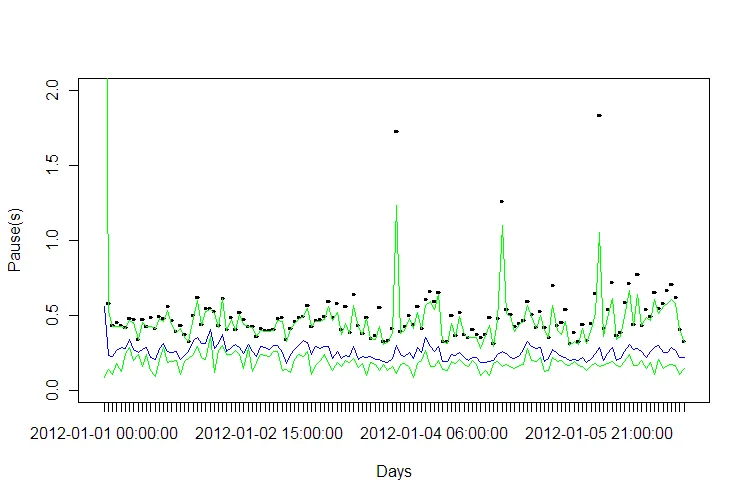
有什么建议吗?(文件可在上面找到)