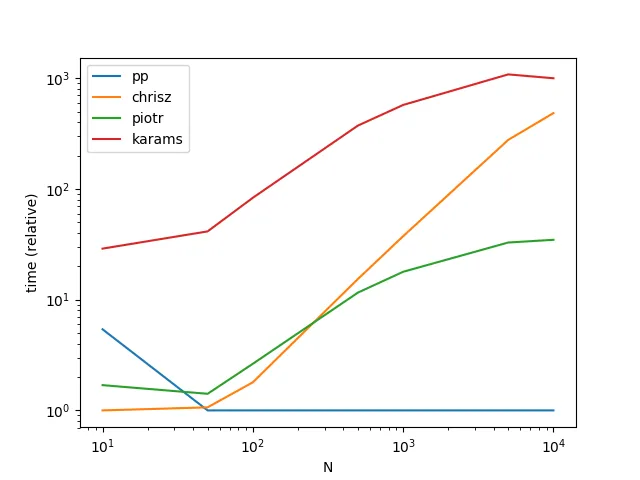
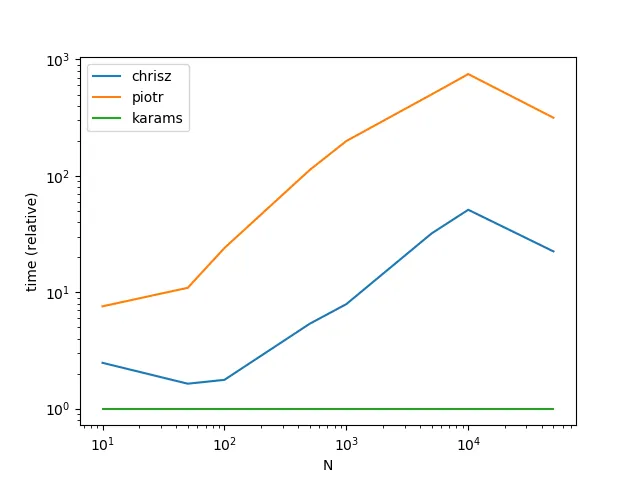
假设我有一个numpy数组,它映射了两种物品类型之间的ID:
[[1, 12],
[1, 13],
[1, 14],
[2, 13],
[2, 14],
[3, 11]]
我希望重新排列这个数组,使得新数组中的每一行表示原始数组中匹配同一ID的所有项目。在这里,每一列将代表原始数组中的一个映射,直到新数组中列数的形状限制为止。如果我们想从上面的数组中获得这个结果,并确保我们只有2列,那么我们会得到:
[[12, 13], #Represents 1 - 14 was not kept as only 2 columns are allowed
[13, 14], #Represents 2
[11, 0]] #Represents 3 - 0 was used as padding since 3 did not have 2 mappings
这里的朴素方法是使用 for 循环,当遇到原始数组中的行时,填充新数组。是否有更有效的方法使用 numpy 的功能来完成这个任务呢?