我正在寻找一种从pandas df中单行解构数据的方法。
我的数据看起来像这样。
编辑:n代表未指定的数字,例如在我的工作数据集中,我有8个图形,给我8 x 2 = 16列我想要转换。
我的数据看起来像这样。
编辑:n代表未指定的数字,例如在我的工作数据集中,我有8个图形,给我8 x 2 = 16列我想要转换。
data = {
'key':['k1', 'k2'],
'plot_name_1':['name', 'name'],
'plot_area_1':[1,2],
'plot_name_2':['name', 'name'],
'plot_area_2':[1,2],
'plot_name_n':['name', 'name'],
'plot_area_n':[1,2]
}
df = pd.DataFrame(data)

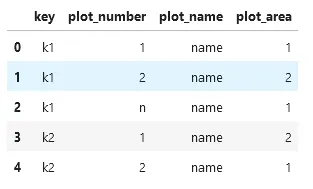
我想在这里结束,添加一个额外的列来标识情节编号:
data = {
'key':['k1','k1','k1', 'k2', 'k2', 'k2'],
'plot_number':['1', '2', 'n','1', '2', 'n'],
'plot_name':['name', 'name','name', 'name','name', 'name'],
'plot_area':[1,2,1,2,1,2],
}
df = pd.DataFrame(data)
pd.wide_to_long(df, stubnames=['plot_name', 'plot_area'], i='key', j='plot_number', sep='_')- mozwayplot_name_n和plot_area_n。 - ScottCn是一个通用术语,用于表示任何数字,但很容易处理(我看到 @Mustafa 已经做到了)。 - mozway