这里有两种选项(使用自我网络和社区检测),基于您提供的教程。
library(udpipe)
data(brussels_reviews)
comments <- subset(brussels_reviews, language %in% "es")
ud_model <- udpipe_download_model(language = "spanish")
ud_model <- udpipe_load_model(ud_model$file_model)
x <- udpipe_annotate(ud_model, x = comments$feedback, doc_id = comments$id)
x <- as.data.frame(x)
cooc <- cooccurrence(x = subset(x, upos %in% c("NOUN", "ADJ")),
term = "lemma",
group = c("doc_id", "paragraph_id", "sentence_id"))
head(cooc)
library(igraph)
library(ggraph)
library(ggplot2)
wordnetwork <- head(cooc, 30)
wordnetwork <- graph_from_data_frame(wordnetwork)
ggraph(wordnetwork, layout = "fr") +
geom_edge_link(aes(width = cooc, edge_alpha = cooc), edge_colour = "pink") +
geom_node_text(aes(label = name), col = "darkgreen", size = 4) +
theme_graph(base_family = "Arial Narrow") +
theme(legend.position = "none") +
labs(title = "Cooccurrences within sentence", subtitle = "Nouns & Adjective")
V(wordnetwork)
ego(wordnetwork, order = 2)
ego(wordnetwork, order = 1, nodes = 10)
cluster_edge_betweenness(wordnetwork, weights = E(wordnetwork)$cooc)
cluster_walktrap(wordnetwork, weights = E(wordnetwork)$cooc, steps = 2)
wordnetwork2 <- as.undirected(wordnetwork)
cluster_fast_greedy(wordnetwork2, weights = E(wordnetwork2)$cooc)
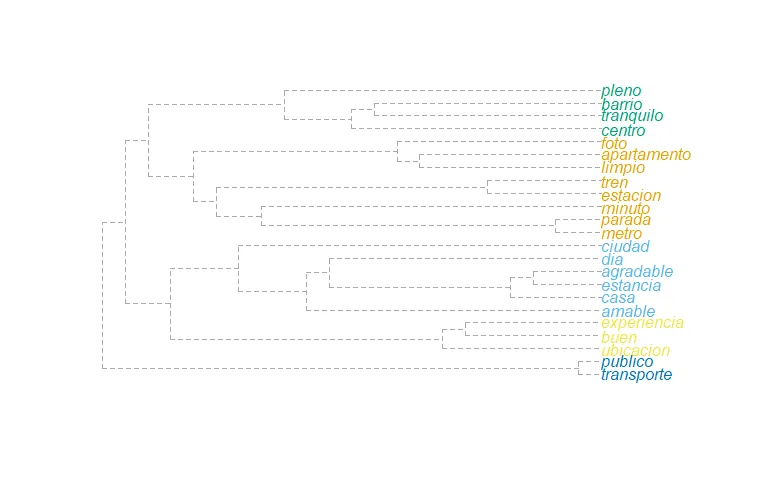
comm <- cluster_fast_greedy(wordnetwork2, weights = E(wordnetwork2)$cooc)
plot_dendrogram(comm)
igraph包中的ego()和cliques()函数了吗?试一试cliques(wordnetwork, min = 2, max = NULL)和ego(wordnetwork)。结果是否符合你的预期? - nghauranproof -> of和of -> concept,proof的二级自我网络将包含of和concept,即使proof和concept没有直接连接。 - nghauran