我是一个有用的助手,可以为您翻译文本。
我正在尝试使用两个numpy数据数组在Python中进行二阶导数计算。
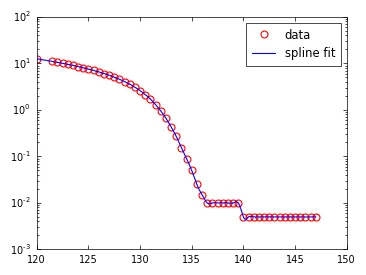
例如,所讨论的数组如下:
我目前有一个函数
我正在尝试使用两个numpy数据数组在Python中进行二阶导数计算。
例如,所讨论的数组如下:
import numpy as np
x = np.array([ 120. , 121.5, 122. , 122.5, 123. , 123.5, 124. , 124.5,
125. , 125.5, 126. , 126.5, 127. , 127.5, 128. , 128.5,
129. , 129.5, 130. , 130.5, 131. , 131.5, 132. , 132.5,
133. , 133.5, 134. , 134.5, 135. , 135.5, 136. , 136.5,
137. , 137.5, 138. , 138.5, 139. , 139.5, 140. , 140.5,
141. , 141.5, 142. , 142.5, 143. , 143.5, 144. , 144.5,
145. , 145.5, 146. , 146.5, 147. ])
y = np.array([ 1.25750000e+01, 1.10750000e+01, 1.05750000e+01,
1.00750000e+01, 9.57500000e+00, 9.07500000e+00,
8.57500000e+00, 8.07500000e+00, 7.57500000e+00,
7.07500000e+00, 6.57500000e+00, 6.07500000e+00,
5.57500000e+00, 5.07500000e+00, 4.57500000e+00,
4.07500000e+00, 3.57500000e+00, 3.07500000e+00,
2.60500000e+00, 2.14500000e+00, 1.71000000e+00,
1.30500000e+00, 9.55000000e-01, 6.65000000e-01,
4.35000000e-01, 2.70000000e-01, 1.55000000e-01,
9.00000000e-02, 5.00000000e-02, 2.50000000e-02,
1.50000000e-02, 1.00000000e-02, 1.00000000e-02,
1.00000000e-02, 1.00000000e-02, 1.00000000e-02,
1.00000000e-02, 1.00000000e-02, 5.00000000e-03,
5.00000000e-03, 5.00000000e-03, 5.00000000e-03,
5.00000000e-03, 5.00000000e-03, 5.00000000e-03,
5.00000000e-03, 5.00000000e-03, 5.00000000e-03,
5.00000000e-03, 5.00000000e-03, 5.00000000e-03,
5.00000000e-03, 5.00000000e-03])
我目前有一个函数
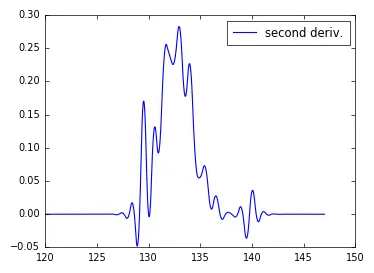
f(x) = y,我想要求它的二阶导数 d^2 y / dx^2。在数值计算中,我知道可以通过插值法解析地求导或使用高阶有限差分方法。如果考虑速度、精度等因素,则两种方法都可以使用。我查看了np.interp()和scipy.interpolate,但并没有成功,因为这只返回拟合的(线性或三次)样条曲线,但不知道如何在该点处获得导数。非常感谢您给出的任何指导。