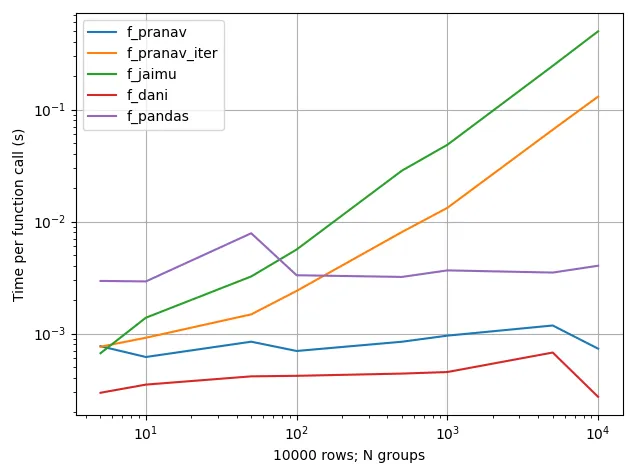
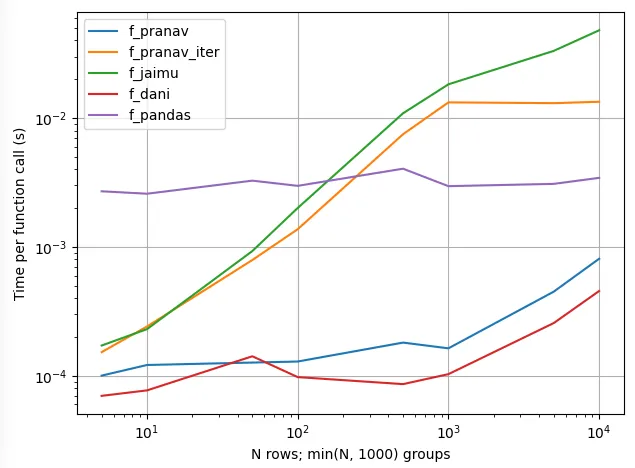
我有以下示例数组,其中包含 x-y 坐标对:
A = np.array([[0.33703753, 3.],
[0.90115394, 5.],
[0.91172016, 5.],
[0.93230994, 3.],
[0.08084283, 3.],
[0.71531777, 2.],
[0.07880787, 3.],
[0.03501083, 4.],
[0.69253184, 4.],
[0.62214452, 3.],
[0.26953094, 1.],
[0.4617873 , 3.],
[0.6495549 , 0.],
[0.84531478, 4.],
[0.08493308, 5.]])
我的目标是通过对每个y值的x值求平均值,将其缩减为一个具有六行的数组,如下所示:
array([[0.6495549 , 0. ],
[0.26953094, 1. ],
[0.71531777, 2. ],
[0.41882167, 3. ],
[0.52428582, 4. ],
[0.63260239, 5. ]])
目前我是通过将其转换为pandas数据框,执行计算,然后再转换回numpy数组来实现的:
>>> df = pd.DataFrame({'x':A[:, 0], 'y':A[:, 1]})
>>> df.groupby('y').mean().reset_index()
y x
0 0.0 0.649555
1 1.0 0.269531
2 2.0 0.715318
3 3.0 0.418822
4 4.0 0.524286
5 5.0 0.632602
有没有使用numpy执行此计算的方法,而不必诉诸于pandas库?