我正在尝试在一张照片上建立静态的增强现实场景,该场景包含了平面上4个已定义的对应点和图像。以下是具体步骤:
1. 用户使用设备相机添加一张图片,假设它捕捉到了一个带有透视效果的矩形。
2. 用户定义矩形在水平平面(以SceneKit中的YOZ表示)上的物理大小,并假设其中心位于世界原点(0, 0, 0),这样我们就可以轻松地找到每个角落的(x,y,z)坐标。
3. 用户为矩形的每个角落定义了图像坐标系下的uv坐标。
4. 创建了一个与图像大小相同、以相同透视可见的矩形的SceneKit场景。
5. 可以向场景中添加其他节点并移动它们。
使用这些数据,我设置了
这将给我一个参考,以便比较我的结果。
为了使用SceneKit构建AR,我需要做以下几点:
3. 相机姿态矩阵。
1. 用户使用设备相机添加一张图片,假设它捕捉到了一个带有透视效果的矩形。
2. 用户定义矩形在水平平面(以SceneKit中的YOZ表示)上的物理大小,并假设其中心位于世界原点(0, 0, 0),这样我们就可以轻松地找到每个角落的(x,y,z)坐标。
3. 用户为矩形的每个角落定义了图像坐标系下的uv坐标。
4. 创建了一个与图像大小相同、以相同透视可见的矩形的SceneKit场景。
5. 可以向场景中添加其他节点并移动它们。

使用这些数据,我设置了
SCNCamera,以获得第三张图上蓝色平面的所需透视效果:let camera = SCNCamera()
camera.xFov = 66
camera.zFar = 1000
camera.zNear = 0.01
cameraNode.camera = camera
cameraAngle = -7 * CGFloat.pi / 180
cameraNode.rotation = SCNVector4(x: 1, y: 0, z: 0, w: Float(cameraAngle))
cameraNode.position = SCNVector3(x: 0, y: 14, z: 42.5)
这将给我一个参考,以便比较我的结果。
为了使用SceneKit构建AR,我需要做以下几点:
- 调整SCNCamera的视场,使其与真实相机的视场相匹配。
- 使用4个世界点(x,0,z)和图像点(u,v)之间的对应关系,计算相机节点的位置和旋转。

H - 单应矩阵;K - 内参数矩阵;[R | t] - 外参数矩阵
我尝试了两种方法来找到相机的变换矩阵:使用OpenCV中的solvePnP和基于4个共面点的单应矩阵手动计算。
手动方法:
1. 找出单应矩阵

这一步已经成功完成,因为世界原点的UV坐标似乎是正确的。
2. 内参矩阵
为了获得iPhone 6的内参矩阵,我使用了this应用程序,它给出了以下100张640*480分辨率图像的结果:

假设输入图像具有4:3的宽高比,我可以根据分辨率缩放上述矩阵。

3. 相机姿态矩阵。
func findCameraPose(homography h: matrix_float3x3, size: CGSize) -> matrix_float4x3? {
guard let intrinsic = intrinsicMatrix(imageSize: size),
let intrinsicInverse = intrinsic.inverse else { return nil }
let l1 = 1.0 / (intrinsicInverse * h.columns.0).norm
let l2 = 1.0 / (intrinsicInverse * h.columns.1).norm
let l3 = (l1+l2)/2
let r1 = l1 * (intrinsicInverse * h.columns.0)
let r2 = l2 * (intrinsicInverse * h.columns.1)
let r3 = cross(r1, r2)
let t = l3 * (intrinsicInverse * h.columns.2)
return matrix_float4x3(columns: (r1, r2, r3, t))
}
结果:
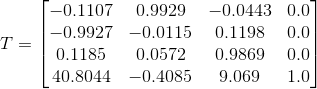
由于我测量了这张特定图片的大致位置和方向,因此我知道变换矩阵,它会给出预期结果,而且与实际结果相差很大:
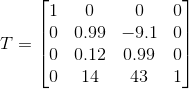
OpenCV方法:
OpenCV中有一个solvePnP函数可以解决这种问题,所以我尝试使用它来代替重复造轮子。
Objective-C++中的OpenCV:
typedef struct CameraPose {
SCNVector4 rotationVector;
SCNVector3 translationVector;
} CameraPose;
+ (CameraPose)findCameraPose: (NSArray<NSValue *> *) objectPoints imagePoints: (NSArray<NSValue *> *) imagePoints size: (CGSize) size {
vector<Point3f> cvObjectPoints = [self convertObjectPoints:objectPoints];
vector<Point2f> cvImagePoints = [self convertImagePoints:imagePoints withSize: size];
cv::Mat distCoeffs(4,1,cv::DataType<double>::type, 0.0);
cv::Mat rvec(3,1,cv::DataType<double>::type);
cv::Mat tvec(3,1,cv::DataType<double>::type);
cv::Mat cameraMatrix = [self intrinsicMatrixWithImageSize: size];
cv::solvePnP(cvObjectPoints, cvImagePoints, cameraMatrix, distCoeffs, rvec, tvec);
SCNVector4 rotationVector = SCNVector4Make(rvec.at<double>(0), rvec.at<double>(1), rvec.at<double>(2), norm(rvec));
SCNVector3 translationVector = SCNVector3Make(tvec.at<double>(0), tvec.at<double>(1), tvec.at<double>(2));
CameraPose result = CameraPose{rotationVector, translationVector};
return result;
}
+ (vector<Point2f>) convertImagePoints: (NSArray<NSValue *> *) array withSize: (CGSize) size {
vector<Point2f> points;
for (NSValue * value in array) {
CGPoint point = [value CGPointValue];
points.push_back(Point2f(point.x - size.width/2, point.y - size.height/2));
}
return points;
}
+ (vector<Point3f>) convertObjectPoints: (NSArray<NSValue *> *) array {
vector<Point3f> points;
for (NSValue * value in array) {
CGPoint point = [value CGPointValue];
points.push_back(Point3f(point.x, 0.0, -point.y));
}
return points;
}
+ (cv::Mat) intrinsicMatrixWithImageSize: (CGSize) imageSize {
double f = 0.84 * max(imageSize.width, imageSize.height);
Mat result(3,3,cv::DataType<double>::type);
cv::setIdentity(result);
result.at<double>(0) = f;
result.at<double>(4) = f;
return result;
}
在 Swift 中的用法:
func testSolvePnP() {
let source = modelPoints().map { NSValue(cgPoint: $0) }
let destination = perspectivePicker.currentPerspective.map { NSValue(cgPoint: $0)}
let cameraPose = CameraPoseDetector.findCameraPose(source, imagePoints: destination, size: backgroundImageView.size);
cameraNode.rotation = cameraPose.rotationVector
cameraNode.position = cameraPose.translationVector
}
输出:
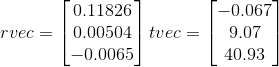

- 这个问题非常相似,但我不明白为什么被接受的答案没有使用内部函数。
- decomposeHomographyMat也没有给我期望中的结果。

solvePnP()。 - CatreesolvePnP())都应该有效。单应法估计的姿态仅适用于平面物体,并且更加复杂。solvePnP()将直接提供相机姿态的旋转和平移向量。 - Catree