我试图对同一生长季内在两个场地进行的田间试验进行一些统计分析。
在两个场地(Site,水平:HF | NW)上,实验设计为RCBD,每个Site内有4个块(Block,水平:1 | 2 | 3 | 4)。共有4种处理方法-3种不同形式的氮肥和一种对照(无氮肥)(Treatment,水平:AN,U,IU,C)。在田间试验期间,有3个明显的时期,始于施肥,以草的收获结束。这些时期已在因子N_app下被赋予水平1 | 2 | 3。
我想测试以下零假设H0的一系列测量结果:
处理(Treatment)(H0)对测量结果没有影响
我特别感兴趣的是两项测量结果:草产量和氨排放。
我尝试使用以下方法运行ANOVA来分析这个问题:
对于这个问题,我有所有上述的担忧,并且数据集不平衡。 在
我不确定如何处理这个额外的复杂性。我倾向于将其分析为2个单独的站点(每个站点的
有人建议我采用线性混合模型方法,但我不熟悉使用这些方法。
我期待您对以上任何问题的看法。谢谢您的时间。
Rory
在两个场地(Site,水平:HF | NW)上,实验设计为RCBD,每个Site内有4个块(Block,水平:1 | 2 | 3 | 4)。共有4种处理方法-3种不同形式的氮肥和一种对照(无氮肥)(Treatment,水平:AN,U,IU,C)。在田间试验期间,有3个明显的时期,始于施肥,以草的收获结束。这些时期已在因子N_app下被赋予水平1 | 2 | 3。
我想测试以下零假设H0的一系列测量结果:
处理(Treatment)(H0)对测量结果没有影响
我特别感兴趣的是两项测量结果:草产量和氨排放。
从这里一个好的平衡数据集开始,以草产量(Dry_tonnes_ha)为例。
可以使用以下代码在R中下载数据:
library(tidyverse)
download.file('https://www.dropbox.com/s/w5ramntwdgpn0e3/HF_NW_grass_yield_data.csv?raw=1', destfile = "HF_NW_grass_yield_data.csv", method = "auto")
raw_data <- read.csv("HF_NW_grass_yield_data.csv", stringsAsFactors = FALSE)
HF_NW_grass <- raw_data %>% mutate_at(vars(Site, N_app, Block, Plot, Treatment), as.factor) %>%
mutate(Date = as.Date(Date, format = "%d/%m/%Y"),
Treatment = factor(Treatment, levels = c("AN", "U", "IU", "C")))
我尝试使用以下方法运行ANOVA来分析这个问题:
model_1 <- aov(formula = Dry_tonnes_ha ~ Treatment * N_app + Site/Block, data = HF_NW_grass, projections = TRUE)
我对此有一些疑虑。
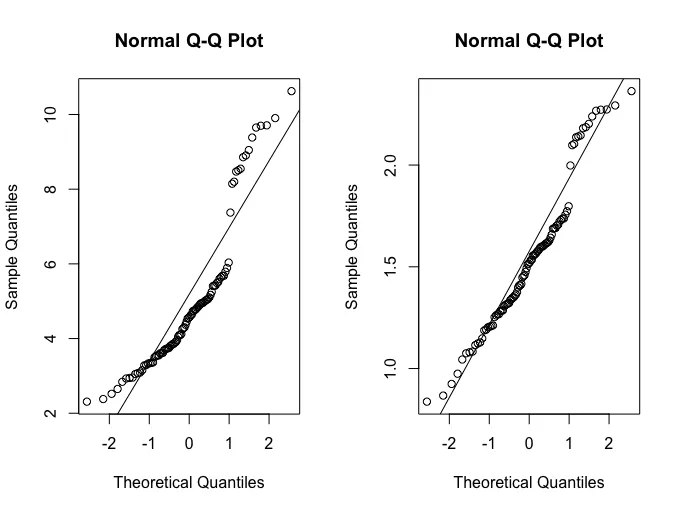
首先,测试假设的最佳方法是什么?对于简单的单向方差分析,我会在因变量(Dry_tonnes_ha)上使用shapiro.test()和bartlett.test()来评估正态性和方差异质性。这里可以使用相同的方法吗?
其次,我担心N_app是重复测量,因为同一地块在3个不同的时期进行了相同的测量 - 最好的方法是将这种重复测量建立到模型中的什么位置?
第三,我不确定在Site中嵌套Block的最佳方法。在两个站点上,Block的级别都是1:4。我是否需要为每个站点设置唯一的Block级别?
我在这里另一个NH3排放数据集。下载R代码:
download.file('https://www.dropbox.com/s/0ax16x95m2z3fb5/HF_NW_NH3_emissions.csv?raw=1', destfile = "HF_NW_NH3_emissions.csv", method = "auto")
raw_data_1 <- read.csv("HF_NW_NH3_emissions.csv", stringsAsFactors = FALSE)
HF_NW_NH3 <- raw_data_1 %>% mutate_at(vars(Site, N_app, Block, Plot, Treatment), as.factor) %>%
mutate(Treatment = factor(Treatment, levels = c("AN", "U", "IU", "C")))
对于这个问题,我有所有上述的担忧,并且数据集不平衡。 在
HF中,对于N_app1 n=3,但对于N_app2和3 n=4。
在NW中,所有N_app级别的n=4。
在NF中,仅对Treatment级别U和IU进行了测量。
在NW中,对Treatment级别AN,U和IU进行了测量。我不确定如何处理这个额外的复杂性。我倾向于将其分析为2个单独的站点(每个站点的
N_app周期不同可能会鼓励采用这种方法)。
我可以在这里使用类型III平方和方差分析吗?有人建议我采用线性混合模型方法,但我不熟悉使用这些方法。
我期待您对以上任何问题的看法。谢谢您的时间。
Rory

Anova? - Rory Shaw