本文旨在为读者提供有关使用Pandas进行SQL风格合并的基础知识,以及如何使用它以及何时不要使用它。
具体而言,本文将介绍以下内容:
本文(以及我在此主题上发布的其他帖子)不会涉及以下内容:
- 性能相关的讨论和时间表(目前为止)。在适当的情况下,大多数更好的替代方案都会被提到。
- 处理后缀、删除额外列、重命名输出和其他特定用例。有其他(更好的)帖子来处理这些问题,所以自己解决吧!
注意
大多数示例默认使用INNER JOIN操作来演示各种功能,除非另有说明。
此外,这里的所有数据框都可以复制和复制,以便您可以使用它们。此外,请参见此帖子,了解如何从剪贴板读取数据框。
最后,所有JOIN操作的视觉表示都是使用Google Drawings手绘的。灵感来自这里。
不要多说 - 直接展示如何使用merge!
设置和基础知识
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
为简化起见,关键列现在使用相同的名称。
INNER JOIN 由以下表示
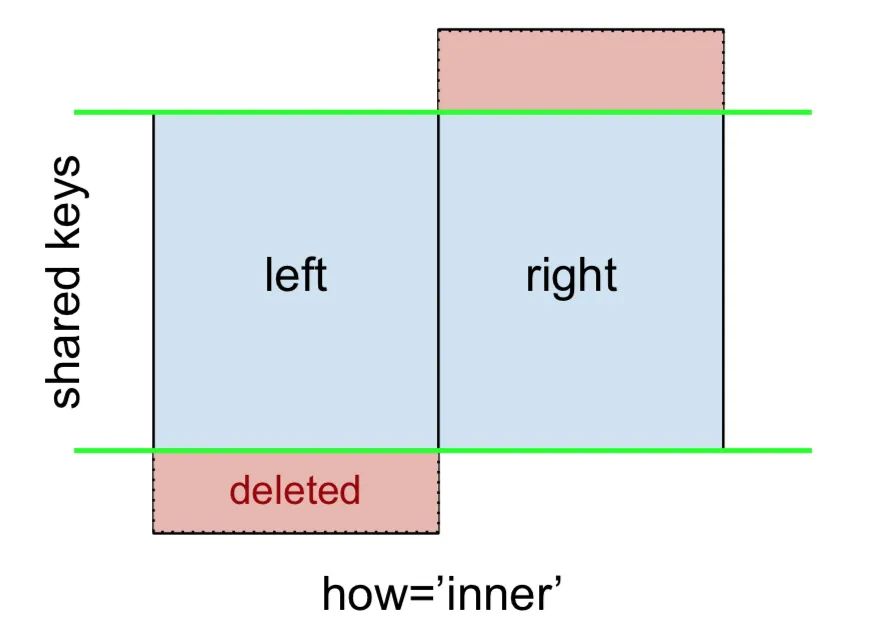
注意:这里以及接下来的所有内容都遵循以下约定:
- 蓝色表示合并结果中存在的行
- 红色表示从结果中排除的行(即已删除)
- 绿色表示在结果中被替换为
NaN的缺失值
要执行内连接,请在左侧DataFrame上调用
merge,将右侧DataFrame和连接键(至少)作为参数指定。
left.merge(right, on='key')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
这将仅返回具有共同键(在此示例中为“B”和“D”)的left和right中的行。
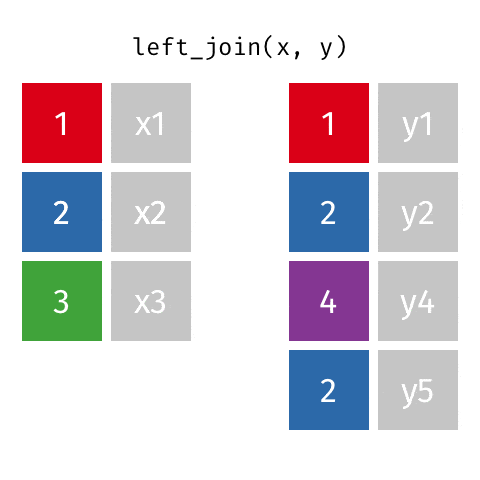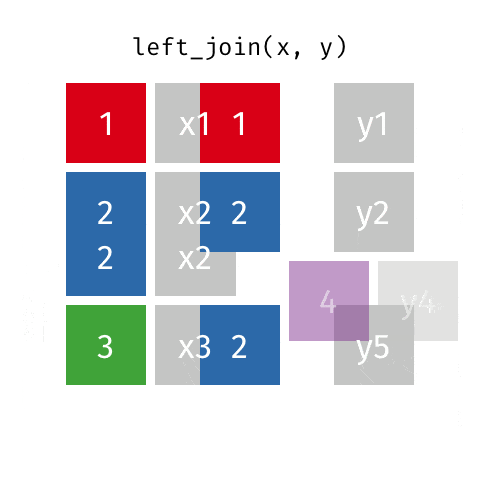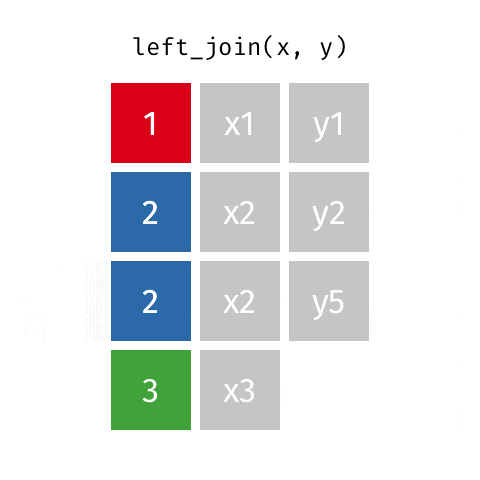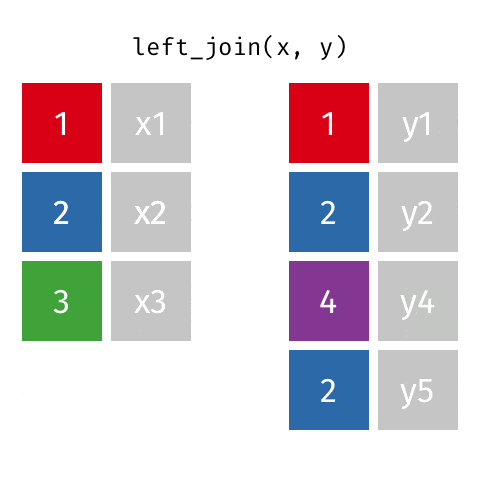
LEFT OUTER JOIN或LEFT JOIN由以下表示:
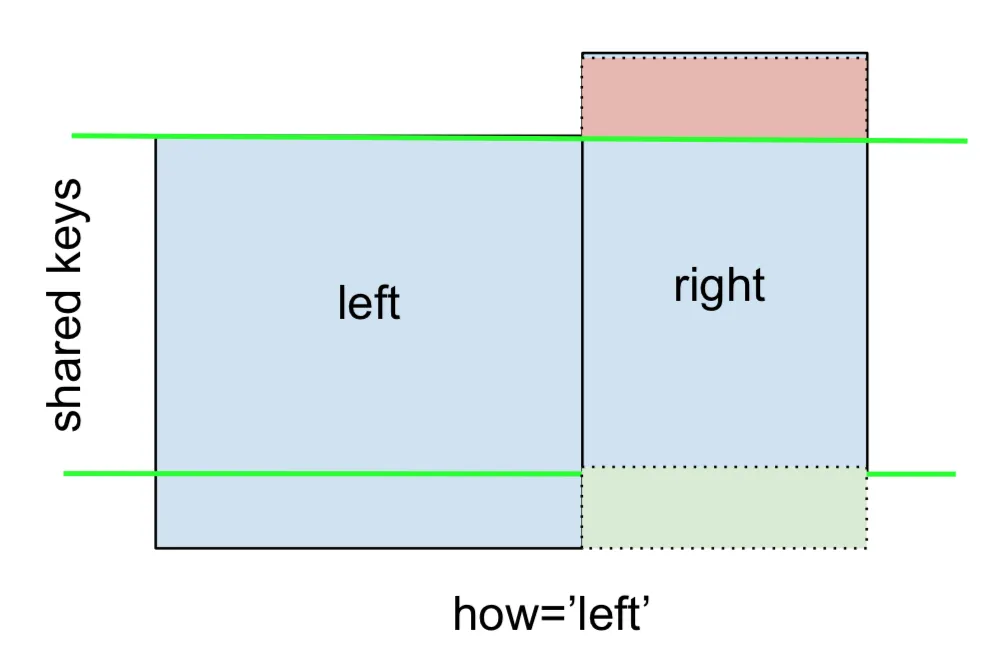
可以通过指定how='left'来执行此操作。
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
请注意这里NaN的位置。如果您指定how='left',则仅使用来自left的键,并且从right缺失的数据将被替换为NaN。
同样地,对于RIGHT OUTER JOIN或RIGHT JOIN,它是...
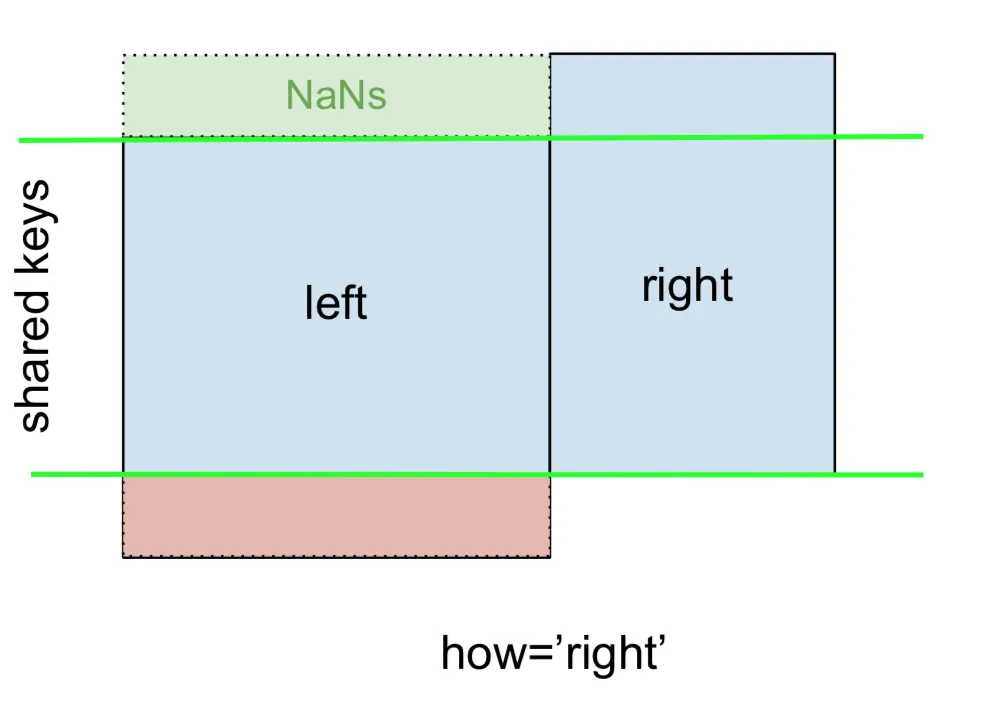
...指定 how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
这里使用了来自
right的键,缺失的数据将被NaN替换。最后,对于
FULL OUTER JOIN,给出如下:
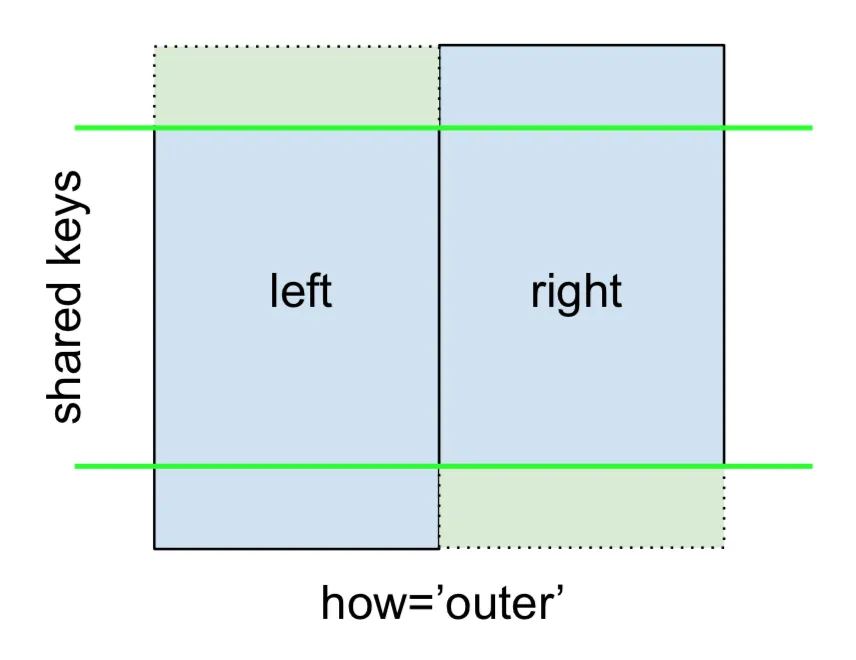
指定how='outer'。
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
这将使用两个框架中的键,并在两者中缺少行的位置插入NaN。
文档很好地总结了这些不同的合并方式:

其他JOIN - 左排斥、右排斥和全排斥/反向连接
如果需要使用左排斥JOIN和右排斥JOIN,需要进行两个步骤。
对于左排斥JOIN,表示为
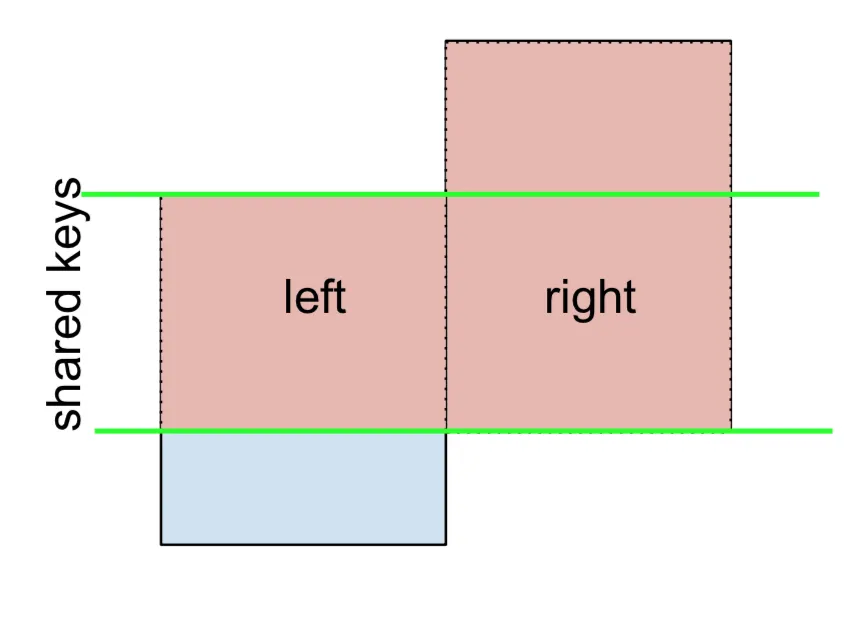
首先执行左外连接,然后过滤只来自left的行(排除右侧的所有内容),
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
在哪里,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 both
同样地,对于RIGHT-Excluding JOIN:
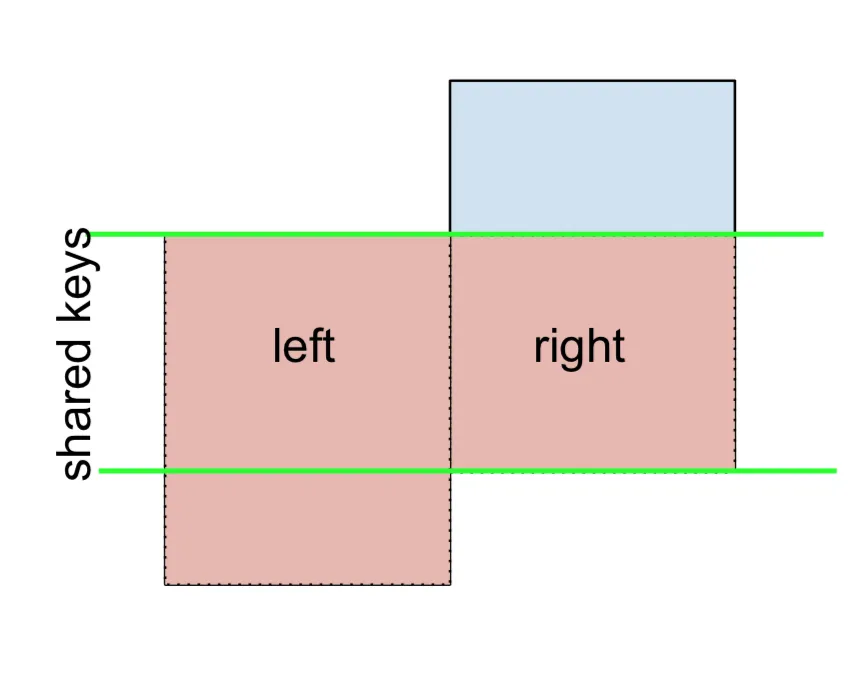
(left.merge(right, on='key', how='right', <b>indicator=True</b>)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357
最后,如果你需要进行只保留左侧或右侧键的合并操作(即执行
ANTI-JOIN),请注意。
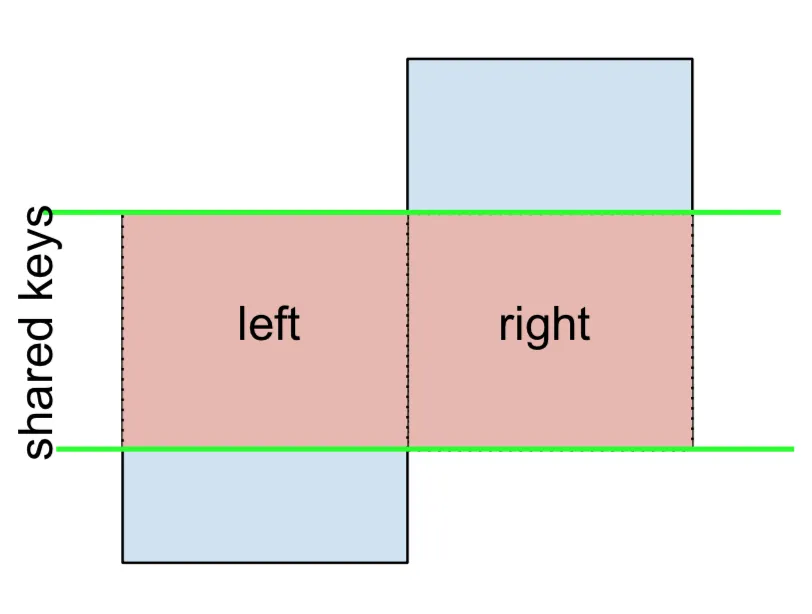
您可以以类似的方式执行此操作——
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
关键列的不同命名
如果关键列的命名不同,例如left使用keyLeft,而right使用keyRight而不是key,那么您需要将left_on和right_on指定为参数,而不是on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
避免输出中的重复列
当从left和right中使用keyLeft和keyRight进行合并时,如果您只想在输出中包含一个 keyLeft或keyRight(但不是两者都包含),则可以首先将索引设置为预备步骤。
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
与刚才的命令输出相比(即
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')的输出),你会注意到
keyLeft列缺失。你可以根据哪个数据框的索引设置为键来确定要保留哪一列。这在执行某些外连接操作时可能很重要。
从一个DataFrame中仅合并单个列
例如,考虑以下情况
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
如果您只需要合并“newcol”(没有其他列),通常可以在合并之前对列进行子集处理:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
如果你正在进行左外连接,更高效的解决方案将涉及使用map:
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
如前所述,这与{{某个东西}}相似,但更快。
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
多列合并
若要在多个列上进行合并,请为on(或适当的left_on和right_on)指定一个列表。
left.merge(right, on=['key1', 'key2'] ...)
或者,如果名称不同,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
其他有用的merge*操作和函数
这一部分只涵盖最基础的内容,旨在激起你的兴趣。有关更多示例和案例,请参阅merge、join和concat的文档以及功能规范链接。
继续阅读
跳转到Pandas合并101中的其他主题以继续学习:
*您在此处。
![on pd.concat([df0, df1])](https://istack.dev59.com/1rb1R.webp)