什么是透视表?
如何进行透视?
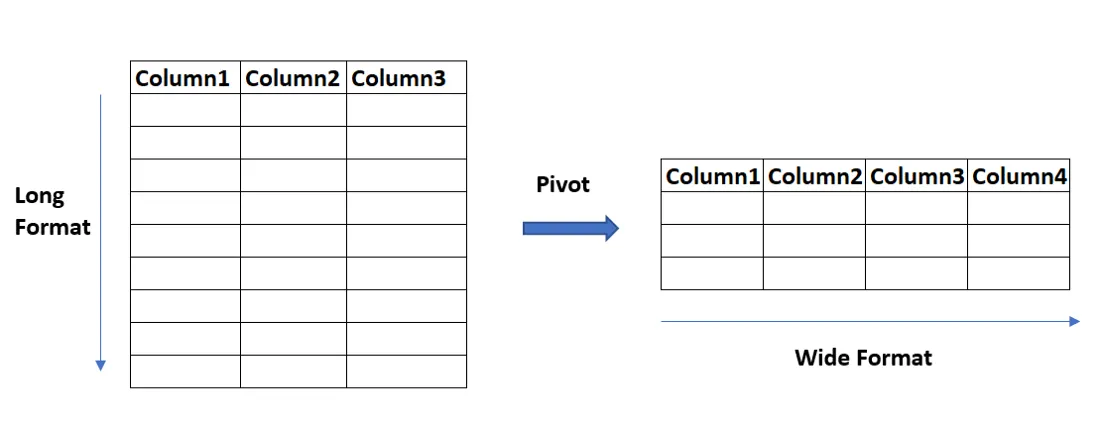
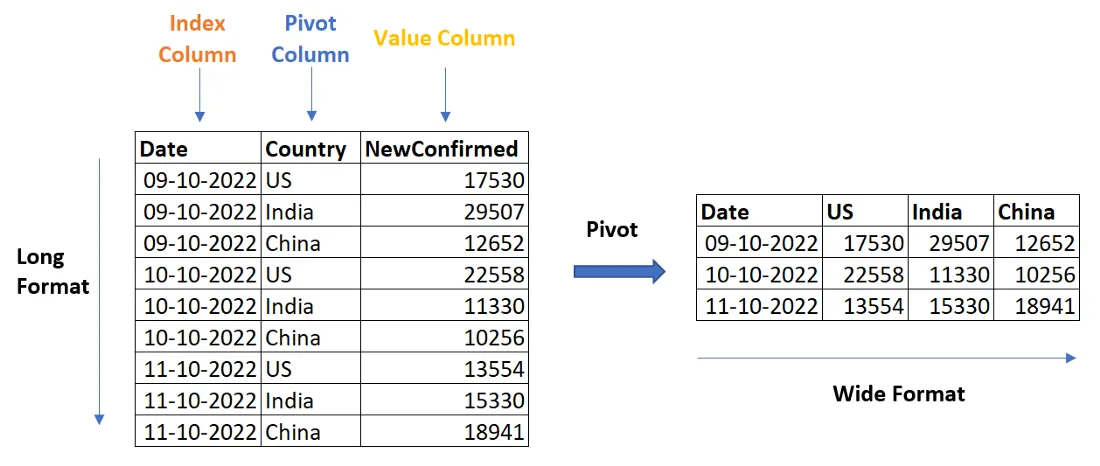
如何将长格式转换为宽格式?
我看到很多关于透视表的问题,即使提问者自己并不知道。要写一个涵盖透视的所有方面的标准问题和答案几乎是不可能的...但是我还是要试一试。
现有问题和答案的问题在于,往往问题的焦点是一个细微之处,而提问者很难将其概括为多个现有好答案的使用。然而,没有一个答案试图给出全面的解释(因为这是一项艰巨的任务)。看看我在Google搜索中的几个例子:
我看到很多关于透视表的问题,即使提问者自己并不知道。要写一个涵盖透视的所有方面的标准问题和答案几乎是不可能的...但是我还是要试一试。
现有问题和答案的问题在于,往往问题的焦点是一个细微之处,而提问者很难将其概括为多个现有好答案的使用。然而,没有一个答案试图给出全面的解释(因为这是一项艰巨的任务)。看看我在Google搜索中的几个例子:
- 如何在Pandas中進行資料框架的樞紐轉換? - 好問題和答案。但是答案只回答了具體問題,解釋很少。
- pandas樞紐轉換表轉換為資料框架 - 提問者關注樞紐轉換的輸出,即列的外觀。提問者希望它的外觀像R一樣。對於Pandas用戶來說,這並不是非常有幫助。
- Pandas資料框架的樞紐轉換,重複的行 - 另一個不錯的問題,但答案只關注一種方法,即
pd.DataFrame.pivot
设置
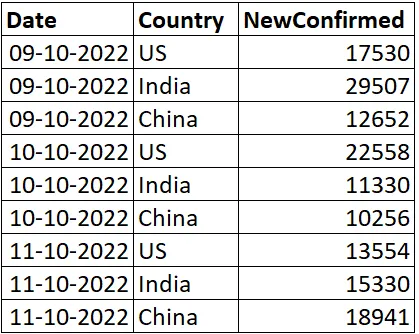
我特意给我的列和相关的列值起了明显的名称,以便与下面的答案中的旋转方式相对应。
import numpy as np
import pandas as pd
from numpy.core.defchararray import add
np.random.seed([3,1415])
n = 20
cols = np.array(['key', 'row', 'item', 'col'])
arr1 = (np.random.randint(5, size=(n, 4)) // [2, 1, 2, 1]).astype(str)
df = pd.DataFrame(
add(cols, arr1), columns=cols
).join(
pd.DataFrame(np.random.rand(n, 2).round(2)).add_prefix('val')
)
print(df)
key row item col val0 val1
0 key0 row3 item1 col3 0.81 0.04
1 key1 row2 item1 col2 0.44 0.07
2 key1 row0 item1 col0 0.77 0.01
3 key0 row4 item0 col2 0.15 0.59
4 key1 row0 item2 col1 0.81 0.64
5 key1 row2 item2 col4 0.13 0.88
6 key2 row4 item1 col3 0.88 0.39
7 key1 row4 item1 col1 0.10 0.07
8 key1 row0 item2 col4 0.65 0.02
9 key1 row2 item0 col2 0.35 0.61
10 key2 row0 item2 col1 0.40 0.85
11 key2 row4 item1 col2 0.64 0.25
12 key0 row2 item2 col3 0.50 0.44
13 key0 row4 item1 col4 0.24 0.46
14 key1 row3 item2 col3 0.28 0.11
15 key0 row3 item1 col1 0.31 0.23
16 key0 row0 item2 col3 0.86 0.01
17 key0 row4 item0 col3 0.64 0.21
18 key2 row2 item2 col0 0.13 0.45
19 key0 row2 item0 col4 0.37 0.70
问题
Why do I get
ValueError: Index contains duplicate entries, cannot reshape?How do I pivot
dfsuch that thecolvalues are columns,rowvalues are the index, and mean ofval0are the values?col col0 col1 col2 col3 col4 row row0 0.77 0.605 NaN 0.860 0.65 row2 0.13 NaN 0.395 0.500 0.25 row3 NaN 0.310 NaN 0.545 NaN row4 NaN 0.100 0.395 0.760 0.24How do I make it so that missing values are
0?col col0 col1 col2 col3 col4 row row0 0.77 0.605 0.000 0.860 0.65 row2 0.13 0.000 0.395 0.500 0.25 row3 0.00 0.310 0.000 0.545 0.00 row4 0.00 0.100 0.395 0.760 0.24Can I get something other than
mean, like maybesum?col col0 col1 col2 col3 col4 row row0 0.77 1.21 0.00 0.86 0.65 row2 0.13 0.00 0.79 0.50 0.50 row3 0.00 0.31 0.00 1.09 0.00 row4 0.00 0.10 0.79 1.52 0.24Can I do more that one aggregation at a time?
sum mean col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4 row row0 0.77 1.21 0.00 0.86 0.65 0.77 0.605 0.000 0.860 0.65 row2 0.13 0.00 0.79 0.50 0.50 0.13 0.000 0.395 0.500 0.25 row3 0.00 0.31 0.00 1.09 0.00 0.00 0.310 0.000 0.545 0.00 row4 0.00 0.10 0.79 1.52 0.24 0.00 0.100 0.395 0.760 0.24Can I aggregate over multiple value columns?
val0 val1 col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4 row row0 0.77 0.605 0.000 0.860 0.65 0.01 0.745 0.00 0.010 0.02 row2 0.13 0.000 0.395 0.500 0.25 0.45 0.000 0.34 0.440 0.79 row3 0.00 0.310 0.000 0.545 0.00 0.00 0.230 0.00 0.075 0.00 row4 0.00 0.100 0.395 0.760 0.24 0.00 0.070 0.42 0.300 0.46Can I subdivide by multiple columns?
item item0 item1 item2 col col2 col3 col4 col0 col1 col2 col3 col4 col0 col1 col3 col4 row row0 0.00 0.00 0.00 0.77 0.00 0.00 0.00 0.00 0.00 0.605 0.86 0.65 row2 0.35 0.00 0.37 0.00 0.00 0.44 0.00 0.00 0.13 0.000 0.50 0.13 row3 0.00 0.00 0.00 0.00 0.31 0.00 0.81 0.00 0.00 0.000 0.28 0.00 row4 0.15 0.64 0.00 0.00 0.10 0.64 0.88 0.24 0.00 0.000 0.00 0.00Or
item item0 item1 item2 col col2 col3 col4 col0 col1 col2 col3 col4 col0 col1 col3 col4 key row key0 row0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.86 0.00 row2 0.00 0.00 0.37 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.50 0.00 row3 0.00 0.00 0.00 0.00 0.31 0.00 0.81 0.00 0.00 0.00 0.00 0.00 row4 0.15 0.64 0.00 0.00 0.00 0.00 0.00 0.24 0.00 0.00 0.00 0.00 key1 row0 0.00 0.00 0.00 0.77 0.00 0.00 0.00 0.00 0.00 0.81 0.00 0.65 row2 0.35 0.00 0.00 0.00 0.00 0.44 0.00 0.00 0.00 0.00 0.00 0.13 row3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.28 0.00 row4 0.00 0.00 0.00 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 key2 row0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.40 0.00 0.00 row2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.13 0.00 0.00 0.00 row4 0.00 0.00 0.00 0.00 0.00 0.64 0.88 0.00 0.00 0.00 0.00 0.00Can I aggregate the frequency in which the column and rows occur together, aka "cross tabulation"?
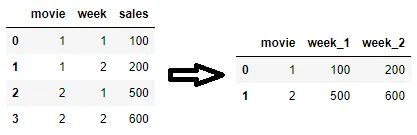
col col0 col1 col2 col3 col4 row row0 1 2 0 1 1 row2 1 0 2 1 2 row3 0 1 0 2 0 row4 0 1 2 2 1How do I convert a DataFrame from long to wide by pivoting on ONLY two columns? Given,
np.random.seed([3, 1415]) df2 = pd.DataFrame({'A': list('aaaabbbc'), 'B': np.random.choice(15, 8)}) df2 A B 0 a 0 1 a 11 2 a 2 3 a 11 4 b 10 5 b 10 6 b 14 7 c 7The expected should look something like
a b c 0 0.0 10.0 7.0 1 11.0 10.0 NaN 2 2.0 14.0 NaN 3 11.0 NaN NaNHow do I flatten the multiple index to single index after
pivot?From
1 2 1 1 2 a 2 1 1 b 2 1 0 c 1 0 0To
1|1 2|1 2|2 a 2 1 1 b 2 1 0 c 1 0 0