我刚开始学习Pandas,想知道groupby和pivot_table函数有什么区别。有人可以帮我理解一下它们之间的区别吗?
Pandas数据框中groupby和pivot_table的区别
108
- user4943236
4个回答
137
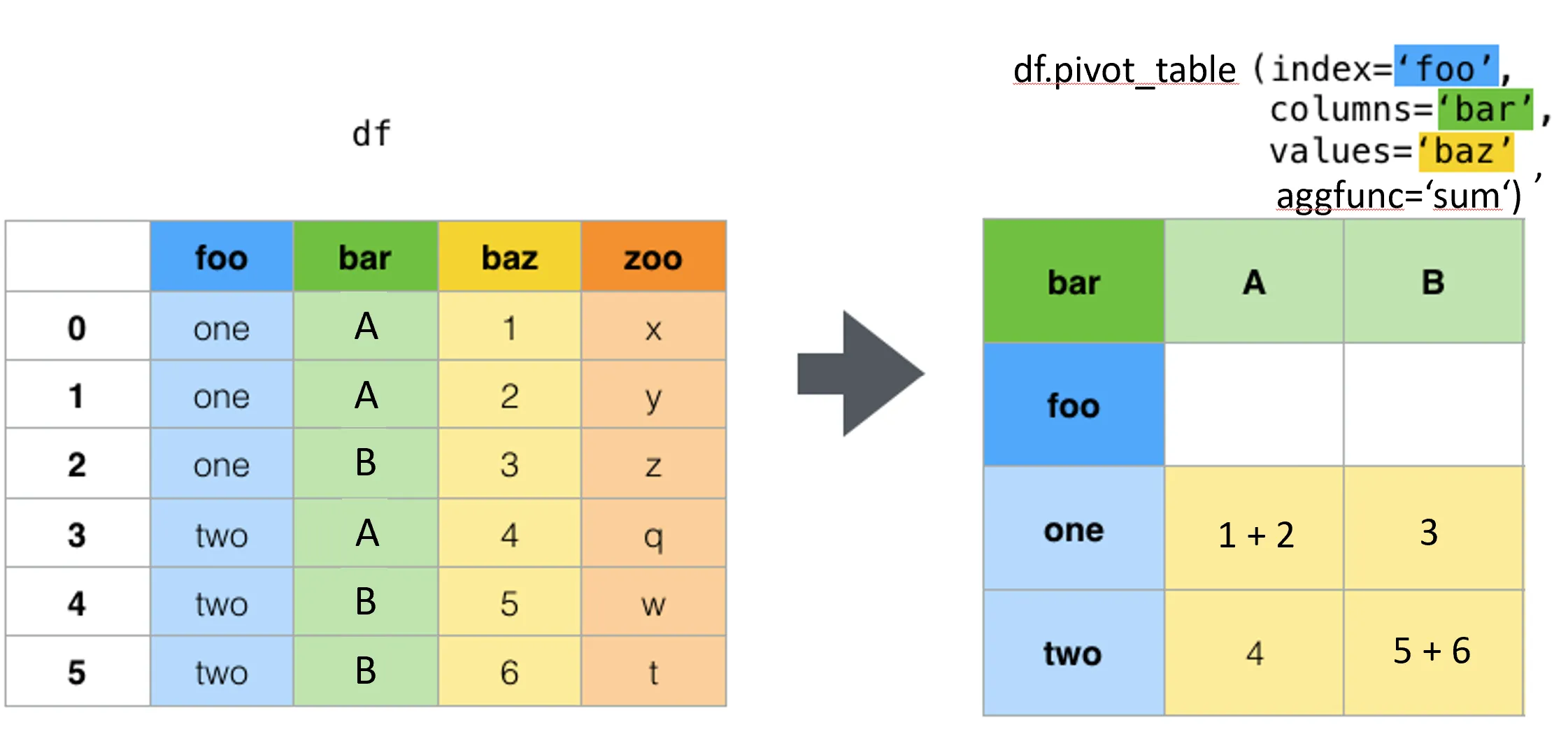
使用 pd.pivot_table(df, index=["a"], columns=["b"], values=["c"], aggfunc=np.sum) 可以聚合你的数据框。不同之处在于结果的形状不同。
使用 pivot_table 时,生成的表格中 a 是行轴,b 是列轴,值是 c 的总和。
示例:
df = pd.DataFrame({"a": [1,2,3,1,2,3], "b":[1,1,1,2,2,2], "c":np.random.rand(6)})
pd.pivot_table(df, index=["a"], columns=["b"], values=["c"], aggfunc=np.sum)
b 1 2
a
1 0.528470 0.484766
2 0.187277 0.144326
3 0.866832 0.650100
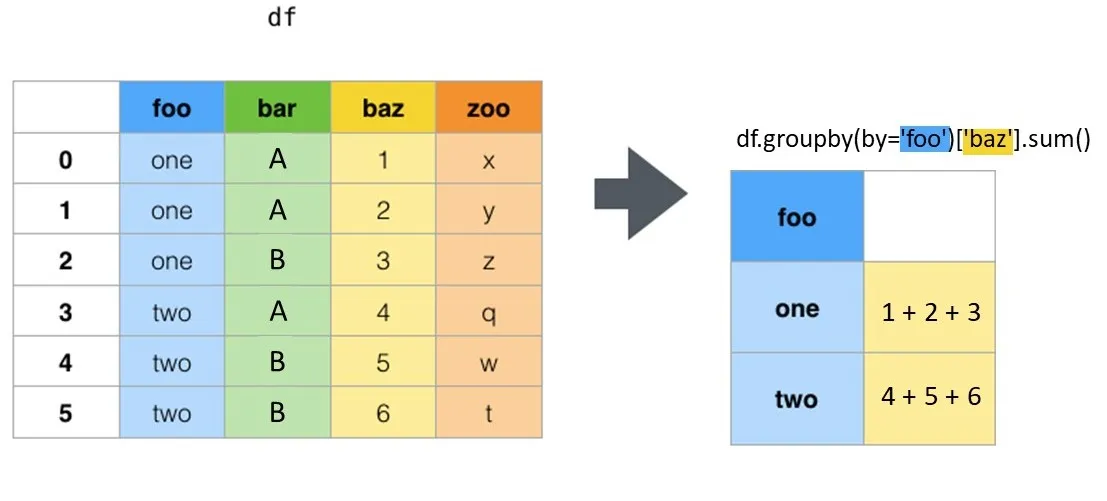
使用groupby,给定的维度被放置在列中,并为这些维度的每个组合创建行。
在这个例子中,我们创建了一个按所有唯一的a和b的组合分组的c值总和的系列。
df.groupby(['a','b'])['c'].sum()
a b
1 1 0.528470
2 0.484766
2 1 0.187277
2 0.144326
3 1 0.866832
2 0.650100
Name: c, dtype: float64
如果我们省略['c'],那么 groupby 的类似用法是创建一个数据框(而不是系列),其中包含按照唯一值分组的所有其他列的总和,分组依据为a和b的唯一值。
print df.groupby(["a","b"]).sum()
c
a b
1 1 0.528470
2 0.484766
2 1 0.187277
2 0.144326
3 1 0.866832
2 0.650100
- David Maust
21
groupby和pivot_table之间存在以下关系(实际上,在底层pivot_table是使用groupby定义的)1:
- pivot_table = groupby + unstack
- groupby = pivot_table + stack
特别是,如果pivot_table()的columns参数未使用,则groupby()和pivot_table()都会产生相同的结果(如果使用相同的聚合函数)。
# sample
df = pd.DataFrame({"a": [1,1,1,2,2,2], "b": [1,1,2,2,3,3], "c": [0,0.5,1,1,2,2]})
# example
gb = df.groupby(['a','b'])[['c']].sum()
pt = df.pivot_table(index=['a','b'], values=['c'], aggfunc='sum')
# equality test
gb.equals(pt) # True <--- no `columns=` kwarg, no `unstack()`
如果你熟悉Microsoft Excel,那么在Python的pandas库中,
groupby和pivot_table的行为类似于Excel中的数据透视表功能:-
groupby:通过by参数(即分组列)来指定行,被聚合的列对应于值,而groupby方法(如mean()、sum()等)对应于在值字段设置中选择的函数。-
pivot_table:通过values参数指定值,index参数指定行,columns参数指定列,aggfunc参数指定在值字段设置中选择的函数。在pandas中,就像在Excel中一样,
groupby会生成一个长表格,而pivot_table会生成一个宽表格。如果将groupby生成的长表格进行unstack操作,就可以得到与pivot_table相同的结果。
1 一般来说,如果我们检查源代码,pivot_table() 内部调用 __internal_pivot_table()。这个函数将索引和列创建成一个单一的平面列表,并将该列表作为分组器调用 groupby()。然后在聚合之后,对列的列表调用 unstack()。
如果没有传递列,就没有需要解开的内容,所以 groupby 和 pivot_table 会产生相同的输出。
这个连接的演示如下:
gb = (
df
.groupby(['a','b'])[['c']].sum()
.unstack(['b'])
)
pt = df.pivot_table(index=['a'], columns=['b'], values=['c'], aggfunc='sum')
gb.equals(pt) # True <--- they produce the same output
由于
stack()是unstack()的逆操作,所以下面的结论也成立:pt = df.pivot_table(index=['a'], columns=['b'], values=['c'], aggfunc='sum').stack(['b'])
gb = df.groupby(['a','b'])[['c']].sum()
pt.equals(gb) # True <--- they produce the same output
总之,根据使用情况,一个比另一个更方便,但它们都可以互相替代使用,在正确应用
stack()/unstack()之后,两者的输出结果都相同。然而,这两种方法之间存在性能差异。简而言之,
pivot_table()比groupby().agg().unstack()慢。您可以从这个答案中了解更多信息。- cottontail
2
13
当你需要同时显示行和列标签的聚合数据时,使用.pivot_table()比.groupby()更为恰当。
.pivot_table()让创建行和列标签变得容易,并且更可取,尽管使用.groupby()也可以通过额外的步骤获得类似的结果。
- kyramichel
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 3 pandas数据框中的Groupby
- 13 使用groupby的结果过滤pandas数据框
- 23 将 Pandas 的 groupby 平均值转换成数据框?
- 12 从Pandas Groupby数据框创建等高线图
- 18 从Pandas的groupby返回聚合数据框。
- 14 在pandas数据框中使用isnull()和groupby()函数
- 3 使用groupby和条件对Pandas数据框进行排序
- 3 基于groupby和pandas series筛选数据框
- 11 Pandas性能:pivot_table与groupby的比较
- 3 pandas中的groupby和reset_index如何改变数据框的索引?
groupby在pivot_table的源代码中实际上就有所体现,因此这个答案不仅最直观,而且我认为它的准确性也是最高的。 - Gene Burinsky