3个回答
72
Pandas是由真正了解人们想要做什么的人编写的。
自从版本0.13以来, 有一个函数pd.read_clipboard,它非常有效地使这个过程“只需运行”。
复制并粘贴问题中以bar foo开头的代码部分(即DataFrame),然后在Python解释器中执行:
In [53]: import pandas as pd
In [54]: df = pd.read_clipboard()
In [55]: df
Out[55]:
bar foo
0 4 1
1 5 2
2 6 3
注意事项
- 不要包含iPython的
In或Out等内容,否则它将无法工作。 - 如果您有一个命名索引,您目前需要添加
engine='python'(请参见GitHub上的this issue)。当索引被命名时,“c”引擎目前是无法正常工作的。 - 它在MultiIndexes方面表现不佳:
请尝试这个:
0 1 2
level1 level2
foo a 0.518444 0.239354 0.364764
b 0.377863 0.912586 0.760612
bar a 0.086825 0.118280 0.592211
这根本不起作用,或者这样:
0 1 2
foo a 0.859630 0.399901 0.052504
b 0.231838 0.863228 0.017451
bar a 0.422231 0.307960 0.801993
这段代码可以运行,但是返回的结果完全不正确!
- LondonRob
4
20
pd.read_clipboard() 很方便。但是,如果你正在编写脚本或笔记本中的代码(并且你希望你的代码在将来可以使用),它可能不太适合。这里有一种替代方法,可以将数据框的输出复制/粘贴到一个新的数据框对象中,以确保 df 比剪贴板的内容更持久:
# py3 only, see below for py2
import pandas as pd
from io import StringIO
d = '''0 1 2 3 4
A Y N N Y
B N Y N N
C N N N N
D Y Y N Y
E N Y Y Y
F Y Y N Y
G Y N N Y'''
df = pd.read_csv(StringIO(d), sep='\s+')
一些注释:
- 三重引号字符串会保留输出中的换行符。
StringIO将输出包装在类文件对象中,这是read_csv所需的。- 将
sep设置为\s+使每个连续的空格块被视为单个分隔符。
更新
以上答案仅适用于Python 3。如果你使用Python 2,请替换导入行:
from io import StringIO
改用以下方法:
from StringIO import StringIO
如果您使用的是旧版本的pandas(v0.24或更早版本),那么有一种简单的方法可以编写与Py2/Py3兼容的上述代码:
import pandas as pd
d = ...
df = pd.read_csv(pd.compat.StringIO(d), sep='\s+')
最新版本的pandas已删除compat模块以及对Python 2的支持。
- tel
4
更好的做法是使用
pd.compat.StringIO,这样就不需要from io import StringIO了。 - jezrael1在Python3中,这完全没有区别(
pd.compat.StringIO is io.StringIO是True),只是一种风格问题(导入语句与更长的参数)。然而,我刚刚检查了一下,结果发现在Python 2中使用io.StringIO会导致令人讨厌的“字节”与“unicode”问题。我认为这绝对是足够好的理由来偏好其中一个,所以我将修改我的答案并使用pd.compat.StringIO。 - tel您缺少导入:根据您的Python版本,即Python 2的
from StringIO import StringIO和Python 3的from io import StringIO,如https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html中所述。使用pandas 0.25.0进行导入将失败,因为https://github.com/pydata/pandas-datareader/issues/655。解决方案是回滚到先前的pandas版本:`pip3 install --upgrade pandas==0.24.2`。 - Hrvoje1@Harvey 显然,
pandas >= 0.25.0已经放弃了compat模块以及对Python 2的支持。我已经更新了我的答案以反映这一点。 - tel1
如果您正在从CSV文件中复制粘贴,该文件具有以下标准条目:
会为您提供正确定义的Pandas数据框。
2016,10,M,0600,0610,13,1020,24
2016,3,F,0300,0330,21,6312,1
2015,4,M,0800,0830,8,7112,30
2015,10,M,0800,0810,19,0125,1
2016,8,M,1500,1510,21,0910,2
2015,10,F,0800,0810,3,8413,5
df =pd.read_clipboard(sep=",", header=None)
df.rename(columns={0: "Name0", 1: "Name1",2:"Name2",3:"Name3",4:"Name4",5:"Name5",6:"Name6",7:"Name7",8:"Name8"})
会为您提供正确定义的Pandas数据框。
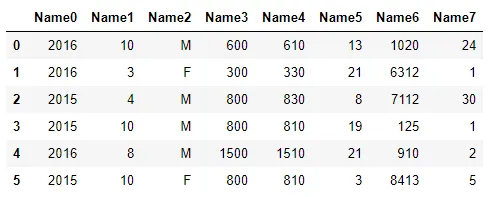
- Hrvoje
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
In [55]和Out[55]一样。我正在使用 Jupyter Notebook,但似乎找不到方法来实现这一点。 - Bowen Liu