最近我阅读了这篇Developer Works文档。
该文档主要介绍了如何有效和正确地定义hashCode()和equals()方法,但是我不明白为什么需要覆盖这两个方法。
我该如何决定高效地实现这些方法?
最近我阅读了这篇Developer Works文档。
该文档主要介绍了如何有效和正确地定义hashCode()和equals()方法,但是我不明白为什么需要覆盖这两个方法。
我该如何决定高效地实现这些方法?
Joshua Bloch 在《Effective Java》中提到:
如果你重写了 equals() 方法,那么必须也要重写 hashCode() 方法。不这样做的话,就会违反 Object.hashCode() 的通用契约,从而导致你的类在与所有基于哈希的集合(包括 HashMap、HashSet 和 Hashtable)一起使用时无法正常工作。
我们可以通过一个例子来理解如果我们重写了 equals() 却没有重写 hashCode(),并试图使用 Map 会发生什么。
假设我们有一个像这样的类,并且当它们的 importantField 相等时,两个 MyClass 对象是相等的(使用 eclipse 生成的 hashCode() 和 equals())
public class MyClass {
private final String importantField;
private final String anotherField;
public MyClass(final String equalField, final String anotherField) {
this.importantField = equalField;
this.anotherField = anotherField;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result
+ ((importantField == null) ? 0 : importantField.hashCode());
return result;
}
@Override
public boolean equals(final Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
final MyClass other = (MyClass) obj;
if (importantField == null) {
if (other.importantField != null)
return false;
} else if (!importantField.equals(other.importantField))
return false;
return true;
}
}
假设你有这个:
MyClass first = new MyClass("a","first");
MyClass second = new MyClass("a","second");
只重写equals
如果只重写equals方法,那么当你调用myMap.put(first,someValue)时,第一个元素将被哈希到某个桶中,当你调用myMap.put(second,someOtherValue)时,它将被哈希到另一个桶中(因为它们具有不同的hashCode)。所以,尽管它们相等,但由于它们没有哈希到同一个桶中,地图无法意识到它们,它们两个都留在地图中。
虽然如果我们重写了hashCode(),就不必重写equals(),但让我们看看在这种特定情况下会发生什么,即我们知道MyClass的两个对象如果它们的importantField相等,则它们相等,但我们没有重写equals()方法。
只重写hashCode
如果只重写hashCode,那么当你调用myMap.put(first,someValue)时,它将获取第一个元素并计算其hashCode,然后将其存储在给定的桶中。然后,当你调用myMap.put(second,someOtherValue)时,根据Map文档,它应该使用第二个元素替换第一个元素,因为它们相等(根据业务要求)。
但问题在于没有重写equals方法,所以当映射哈希second并遍历桶查找是否存在一个对象k使得second.equals(k)为真时,它将不会发现任何对象,因为second.equals(first)将是false。
希望解释清楚了。
equals方法,那么你需要覆盖hashCode方法,但反过来则不成立。 - akhil_mittalequals(Object)方法是相等的,则在这两个对象上调用hashCode方法必须产生相同的整数结果。”当然,并非所有代码都会使用所有协议的所有部分,但从正式角度而言,仍然是一种违规行为,我认为它是潜在的 bug。 - aioobeHashMap 和 HashSet 等集合类型使用对象的 哈希码 值来确定它应该如何存储在集合内,而且 哈希码 再次被用于定位其所属集合中的对象。
哈希检索是一个两步过程:
hashCode())equals())这里有一个简单的例子说明为什么我们应该覆盖 equals() 和 hashCode()。
考虑一个 Employee 类,它有两个字段:年龄和姓名。
public class Employee {
String name;
int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object obj) {
if (obj == this)
return true;
if (!(obj instanceof Employee))
return false;
Employee employee = (Employee) obj;
return employee.getAge() == this.getAge()
&& employee.getName() == this.getName();
}
// commented
/* @Override
public int hashCode() {
int result=17;
result=31*result+age;
result=31*result+(name!=null ? name.hashCode():0);
return result;
}
*/
}
现在创建一个类,将Employee对象插入到HashSet中,并测试该对象是否存在。
public class ClientTest {
public static void main(String[] args) {
Employee employee = new Employee("rajeev", 24);
Employee employee1 = new Employee("rajeev", 25);
Employee employee2 = new Employee("rajeev", 24);
HashSet<Employee> employees = new HashSet<Employee>();
employees.add(employee);
System.out.println(employees.contains(employee2));
System.out.println("employee.hashCode(): " + employee.hashCode()
+ " employee2.hashCode():" + employee2.hashCode());
}
}
它将打印出以下内容:
false
employee.hashCode(): 321755204 employee2.hashCode():375890482
现在取消注释hashcode()方法,执行相同的操作,输出将是:
true
employee.hashCode(): -938387308 employee2.hashCode():-938387308
现在你明白了吗,为什么如果两个对象被认为是相等的,它们的哈希码也必须相等呢?否则,你永远无法找到该对象,因为在Object类中默认的哈希码方法几乎总是为每个对象生成一个唯一的数字,即使equals()方法被重写以这样的方式使得两个或更多对象被认为是相等的。如果它们的哈希码不反映这一点,那么对象的相等性就没有意义了。所以再说一遍:如果两个对象相等,它们的哈希码也必须相等。
hashCode()也无关紧要。 - slimequals和hashCode方面发生的情况。 - Panagiotis Bougioukos为什么要重写equals()方法
在Java中,我们不能改变==、+=、-+等操作符的行为。它们有固定的行为方式。所以我们在这里只关注操作符==。
操作符==的工作原理:
它会检查我们比较的两个引用是否指向内存中的同一实例。只有当这两个引用表示同一内存实例时,操作符==才会返回true。
现在让我们考虑以下例子:
public class Person {
private Integer age;
private String name;
..getters, setters, constructors
}
假设您的程序在不同位置构建了两个“Person”对象并希望进行比较。
Person person1 = new Person("Mike", 34);
Person person2 = new Person("Mike", 34);
System.out.println ( person1 == person2 ); --> will print false!
从商业角度来看,这两个对象看起来是一样的,对于JVM来说它们并不相同。由于它们都是用new关键字创建的实例,它们位于内存中的不同段。因此,操作符==将返回false。
但如果我们不能重写==操作符,我们如何告诉JVM我们希望将这两个对象视为相同呢?这时就需要用到.equals()方法。
您可以重写equals()方法,以检查某些对象是否具有特定字段的相同值,以被认为是相等的。
您可以选择要比较哪些字段。例如,如果我们说当两个Person对象拥有相同的年龄和姓名时,它们将是相同的,那么IDE将自动生成以下内容来自动生成equals():
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
name.equals(person.name);
}
让我们回到之前的例子
Person person1 = new Person("Mike", 34);
Person person2 = new Person("Mike", 34);
System.out.println ( person1 == person2 ); --> will print false!
System.out.println ( person1.equals(person2) ); --> will print true!
因此,我们不能重载“ ==”运算符以按我们想要的方式比较对象,但Java给了我们另一种方法,即equals()方法,我们可以按照自己的意愿进行覆盖。
请记住,如果我们在我们的类中不提供自定义版本的.equals()(也就是覆盖),那么预定义的Object类的.equals()和==运算符将表现完全相同。
从Object继承的默认equals()方法将检查所比较的两个实例在内存中是否相同!
为什么要覆盖hashCode()方法
Java中的一些数据结构,如HashSet、HashMap,根据应用于这些元素的哈希函数来存储它们。哈希函数是hashCode()。
如果我们可以选择覆盖.equals()方法,那么我们必须也可以选择覆盖hashCode()方法。这其中有一个原因。
从Object继承的hashCode()方法的默认实现认为内存中所有对象都是唯一的!
让我们回到那些哈希数据结构。这些数据结构有一个规则。
HashSet不能包含重复值,HashMap不能包含重复的键
HashSet背后是由一个HashMap实现的,HashSet中的每个值都存储为HashMap中的一个键。
因此,我们必须了解HashMap的工作原理。
简单来说,HashMap是一个有一些桶的本地数组。每个桶都有一个链表。在那个链表中存储了我们的键。HashMap通过应用hashCode()方法定位每个键的正确链表,然后遍历该链表中的所有元素,并对每个这些元素应用equals()方法以检查该元素是否已经存在。不允许有重复的键。
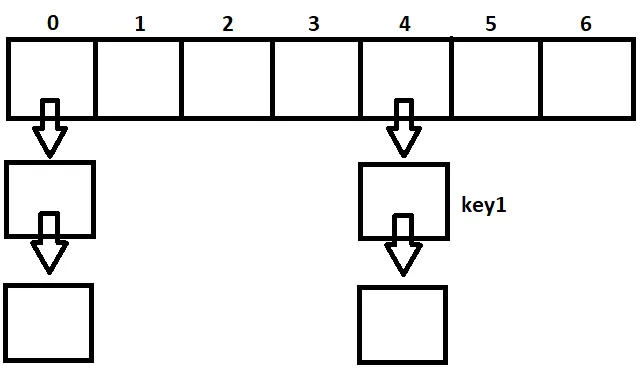
当我们将某些东西放入HashMap时,键存储在其中一个链表中。哪个链表中存储该键,取决于对该键应用hashCode()方法所返回的结果。因此,如果key1.hashCode()的结果为4,则该key1将存储在数组的第4个桶中,该桶中存在该链表。
默认情况下,hashCode()方法为每个不同的实例返回不同的结果。如果我们有默认的equals(),它的行为类似于==,即将内存中所有实例视为不同的对象,则我们没有任何问题。
但在我们之前的例子中,我们说我们希望Person实例在其年龄和姓名匹配时被认为是相等的。
Person person1 = new Person("Mike", 34);
Person person2 = new Person("Mike", 34);
System.out.println ( person1.equals(person2) ); --> will print true!
现在让我们创建一个映射,用实例作为键和一些字符串作为对应值
Map<Person, String> map = new HashMap();
map.put(person1, "1");
map.put(person2, "2");
在 Person 类中,我们没有重写 hashCode 方法,但是我们已经重写了equals方法。由于默认的 hashCode 方法为不同的 Java 实例提供不同的结果,person1.hashCode() 和 person2.hashCode() 很有可能具有不同的结果。
这就导致我们的 map 可能会将这些人分别存储在不同的链表中。
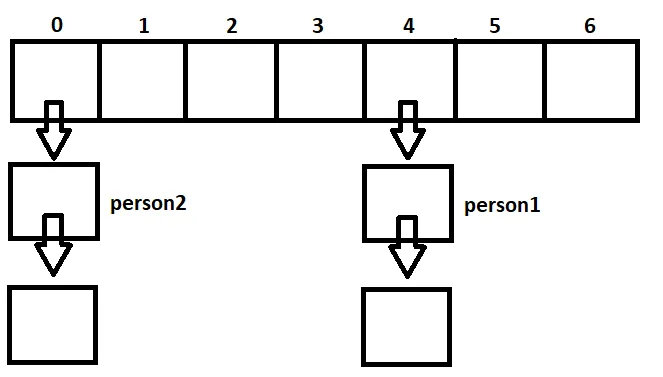
这与 HashMap 的逻辑相违背。
HashMap 不允许拥有多个相等的键!
但我们的 HashMap 现在存在这个问题,原因是从 Object 类继承而来的默认的 hashCode() 方法不够用。特别是我们已经在 Person 类中重写了 equals() 方法之后。
这就是为什么在我们重写 equals() 方法之后,必须重写 hashCode() 方法的原因。
现在让我们来解决这个问题。让我们重写我们的 hashCode() 方法,使其考虑与 equals() 方法相同的字段,即 age, name。
public class Person {
private Integer age;
private String name;
..getters, setters, constructors
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
name.equals(person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
现在让我们再试一次将这些键保存到HashMap中
Map<Person, String> map = new HashMap();
map.put(person1, "1");
map.put(person2, "2");
person1.hashCode()和person2.hashCode()的值一定相同,假设为0。
HashMap会进入到桶0,并将person1作为键,值为“1”的项保存在链表中。对于第二个put操作,HashMap会智能地再次进入桶0,尝试保存键为person2、值为“2”的项,但发现已经存在一个相等的键。因此,它会覆盖前一个键。因此,最终我们的HashMap中只有person2这个键。
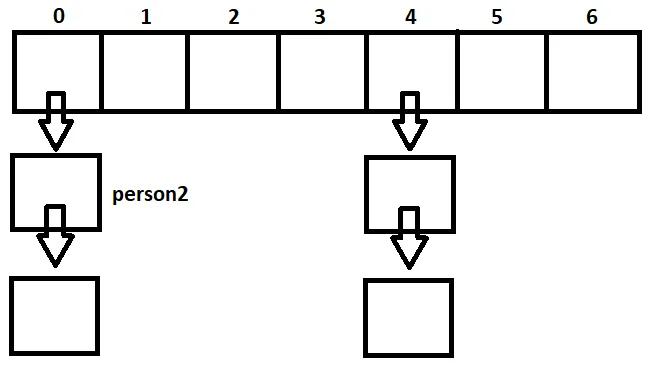
现在,我们遵循HashMap规则:不允许有多个相等的键!
..getters, setters, constructors。在使用 Objects.hash(name, age) 中的字段时,应始终将其设为 final。否则,对象的哈希码可能会被更改,这将导致 Set/Map 等许多问题。请参见 https://docs.oracle.com/javase/6/docs/api/java/lang/Object.html#hashCode()。 - Nexen身份与相等性不同。
==测试身份。equals(Object obj)方法比较相等性测试(即我们需要通过重写该方法来判断相等性)。为什么需要在Java中重写equals和hashCode方法?
首先,我们必须了解equals方法的用途。
为了确定两个对象之间的差异,我们需要重写equals方法。
例如:
Customer customer1=new Customer("peter");
Customer customer2=customer1;
customer1.equals(customer2); // returns true by JVM. i.e. both are refering same Object
------------------------------
Customer customer1=new Customer("peter");
Customer customer2=new Customer("peter");
customer1.equals(customer2); //return false by JVM i.e. we have two different peter customers.
------------------------------
Now I have overriden Customer class equals method as follows:
@Override
public boolean equals(Object obj) {
if (this == obj) // it checks references
return true;
if (obj == null) // checks null
return false;
if (getClass() != obj.getClass()) // both object are instances of same class or not
return false;
Customer other = (Customer) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name)) // it again using bulit in String object equals to identify the difference
return false;
return true;
}
Customer customer1=new Customer("peter");
Customer customer2=new Customer("peter");
Insteady identify the Object equality by JVM, we can do it by overring equals method.
customer1.equals(customer2); // returns true by our own logic
现在hashCode方法更易于理解了。
hashCode方法产生整数以便将对象存储在数据结构中,例如HashMap、HashSet。
假设我们已经重写了Customer的equals方法,就像上面那样:
customer1.equals(customer2); // returns true by our own logic
在处理数据结构时,当我们将对象存储在桶中("bucket"是文件夹的花哨名称)时,如果使用内置哈希技术,则对于上述两个客户端,它会生成两个不同的哈希码。因此,我们将相同的identical对象存储在两个不同的位置。为了避免这种问题,我们应该根据以下原则覆盖hashCode方法。
简单来说,Object类中的equals方法检查引用是否相等,而你的类的两个实例在属性相等时仍然可以是语义上相等的。比如说,当你将对象放入使用equals和hashcode的容器中时(例如HashMap和Set),这一点就变得很重要了。假设我们有一个类:
public class Foo {
String id;
String whatevs;
Foo(String id, String whatevs) {
this.id = id;
this.whatevs = whatevs;
}
}
我们创建了两个具有相同id的实例:
Foo a = new Foo("id", "something");
Foo b = new Foo("id", "something else");
如果没有重写equals方法,我们会得到以下结果:
是正确的吗?也许,如果这正是你想要的结果。但是假设我们希望具有相同id的对象在两个不同的实例中也被视为相同的对象,那么我们需要重写equals(和hashcode)方法:
public class Foo {
String id;
String whatevs;
Foo(String id, String whatevs) {
this.id = id;
this.whatevs = whatevs;
}
@Override
public boolean equals(Object other) {
if (other instanceof Foo) {
return ((Foo)other).id.equals(this.id);
}
}
@Override
public int hashCode() {
return this.id.hashCode();
}
}
关于实现equals和hashcode,我建议使用Guava的辅助方法
让我用简单的话来解释这个概念。
首先,从更广泛的视角来看,我们有集合,而HashMap是集合中的一种数据结构。
为了理解为什么我们必须同时重写equals和hashCode方法,我们需要先了解什么是HashMap以及它的作用。
HashMap是一种数据结构,它将键值对的数据以数组方式存储。假设是a[],其中“a”中的每个元素都是一个键值对。
此外,上述数组中的每个索引都可以是链接列表,因此在一个索引处有多个值。
现在,为什么要使用HashMap呢?
如果我们必须在大数组中搜索,那么逐个搜索将不高效,所以哈希技术告诉我们,让我们对数组进行一些逻辑预处理并根据该逻辑分组元素,即散列。
例如:我们有一个数组1,2,3,4,5,6,7,8,9,10,11,我们应用哈希函数mod 10,所以1,11将被分组在一起。因此,如果我们要在先前的数组中搜索11,则必须迭代完整的数组,但是当我们对其进行分组时,我们限制了迭代范围,从而提高了速度。用于存储上述所有信息的数据结构可以简单地看作是一个二维数组。那么,put方法的作用是首先为给定的键生成hashCode以决定值应该放在哪个索引中。如果该索引中没有任何内容,则新值将添加到该位置;如果该位置已经有内容,则新值应该添加到该索引处链接列表的末尾。但请记住,根据HashMap的期望行为,不应添加重复项。假设您有两个整数对象aa=11,bb=11。
由于每个对象都派生自Object类,比较两个对象的默认实现是比较引用而不是对象内部的值。因此,在上述情况下,虽然语义上相等,但两者将无法通过相等性测试,并且可能存在具有相同hashCode和相同值的两个对象,从而创建重复项。如果我们进行覆盖,则可以避免添加重复项。 您还可以参考详细工作。
import java.util.HashMap;
public class Employee {
String name;
String mobile;
public Employee(String name,String mobile) {
this.name = name;
this.mobile = mobile;
}
@Override
public int hashCode() {
System.out.println("calling hascode method of Employee");
String str = this.name;
int sum = 0;
for (int i = 0; i < str.length(); i++) {
sum = sum + str.charAt(i);
}
return sum;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
System.out.println("calling equals method of Employee");
Employee emp = (Employee) obj;
if (this.mobile.equalsIgnoreCase(emp.mobile)) {
System.out.println("returning true");
return true;
} else {
System.out.println("returning false");
return false;
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
Employee emp = new Employee("abc", "hhh");
Employee emp2 = new Employee("abc", "hhh");
HashMap<Employee, Employee> h = new HashMap<>();
//for (int i = 0; i < 5; i++) {
h.put(emp, emp);
h.put(emp2, emp2);
//}
System.out.println("----------------");
System.out.println("size of hashmap: "+h.size());
}
}
hashCode() :
如果您只重写了hashCode() 方法,那么程序不会发生任何变化,因为这个方法总是返回一个新的hashCode, 而且这个方法是从Object类继承而来的。
equals() :
如果您只重写了equals() 方法, 如果 a.equals(b) 为true,则意味着a和b的hashCode必须相同,但事实并非如此,因为您没有重写hashCode() 方法。
注意: Object类的hashCode() 方法总是返回一个新的hashCode。
所以当您需要将对象用于基于哈希的集合中时,您必须同时重写equals() 和 hashCode() 方法。
Java规定:
“如果两个对象使用Object类的equals方法相等,则hashcode方法应该为这两个对象返回相同的值。”
因此,如果我们在类中重写了equals()方法,就应该同时重写hashcode()方法以遵循此规则。
在Hashtable等数据结构中,equals()和hashcode()方法都用于将键值对存储为值。如果我们仅重写其中一个方法而不是另一个方法,则如果我们将该对象用作键,Hashtable可能无法按预期工作。
继续完善 @Lombo 的回答:
何时需要重写 equals() 方法?
Object 的默认 equals() 实现为
public boolean equals(Object obj) {
return (this == obj);
}
equals() 方法,并给出自己的相等条件来实现自定义对象的比较。myMap.put(first,someValue)
myMap.contains(second); --> But it should be the same since the key are the same.But returns false!!! How?
second的哈希码是否与first相同。只有在值相同时,它才会继续在同一个桶中检查它们是否相等。contains()检查hashCode(),只有当它们相同时才会调用您的equals()方法。
为什么我们不能让HashMap在所有桶中都检查相等性?这样我就不需要重写hashCode()了!
那么您就错过了基于哈希的集合的要点。
考虑以下内容:Your hashCode() implementation : intObject%9.
Bucket 1 : 1,10,19,... (in thousands)
Bucket 2 : 2,20,29...
Bucket 3 : 3,21,30,...
...
假设你想知道该地图是否包含关键字10。 你是想搜索所有桶?还是只想搜索一个桶?
根据哈希代码,您可以确定如果10存在,则必须存在于Bucket 1中。 因此,只有Bucket 1将被搜索!!