{kind=link}
{kind=link}
{kind=link}
2个回答
3
由于轮廓是连接在一起的,
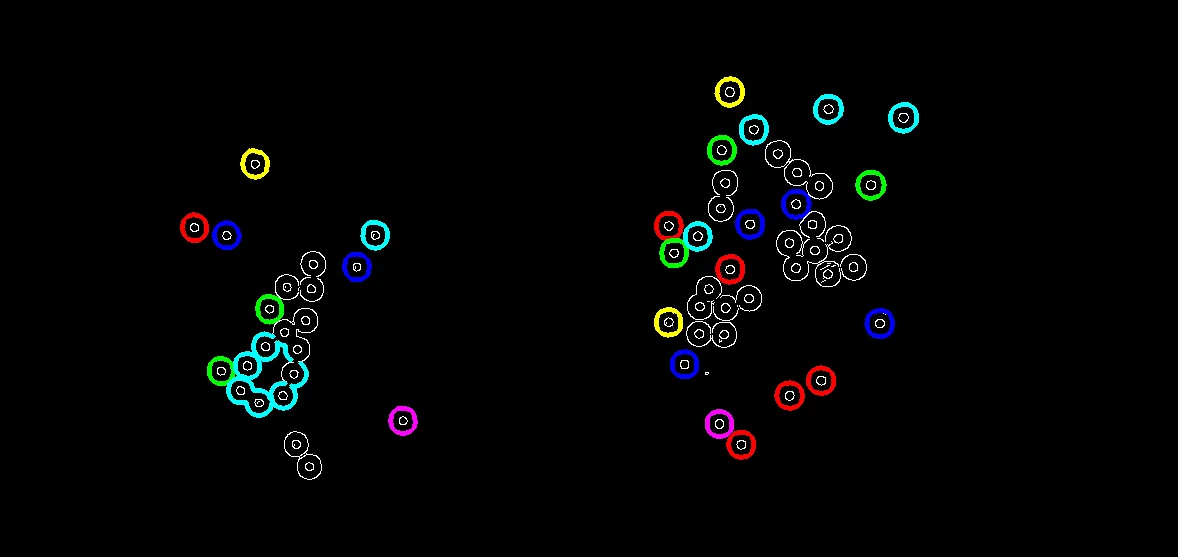
输入图像
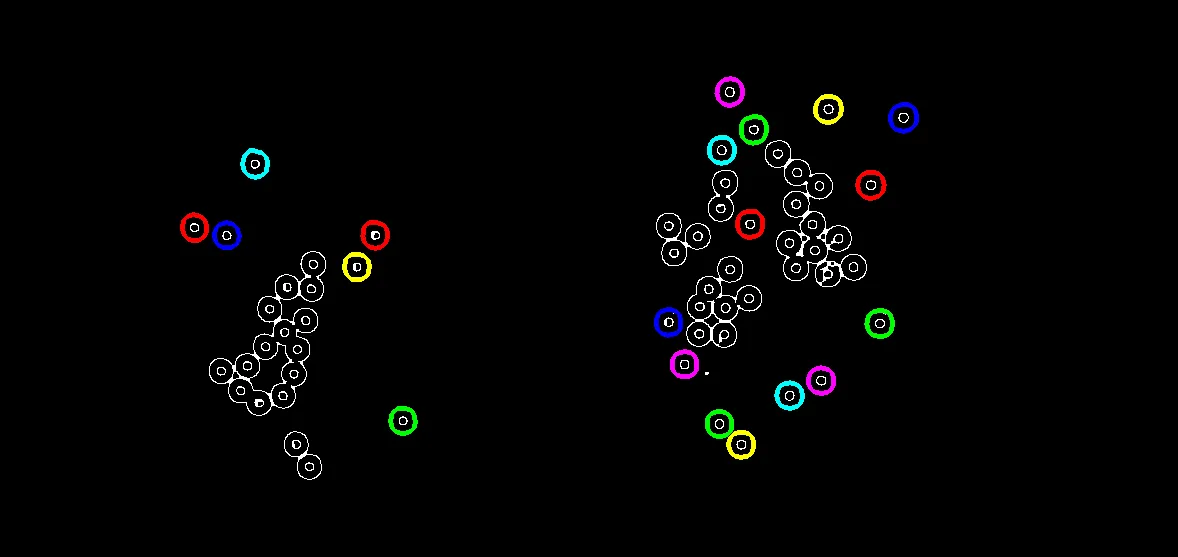
findContours将检测到连接的轮廓作为单个轮廓而不是独立的分离圆。当您有连接的轮廓时,一个潜在的方法是使用Watershed来标记和检测每个轮廓。以下是结果:输入图像

输出

代码
import cv2
import numpy as np
from skimage.feature import peak_local_max
from skimage.morphology import watershed
from scipy import ndimage
# Load in image, convert to gray scale, and Otsu's threshold
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
# Compute Euclidean distance from every binary pixel
# to the nearest zero pixel then find peaks
distance_map = ndimage.distance_transform_edt(thresh)
local_max = peak_local_max(distance_map, indices=False, min_distance=20, labels=thresh)
# Perform connected component analysis then apply Watershed
markers = ndimage.label(local_max, structure=np.ones((3, 3)))[0]
labels = watershed(-distance_map, markers, mask=thresh)
# Iterate through unique labels
for label in np.unique(labels):
if label == 0:
continue
# Create a mask
mask = np.zeros(gray.shape, dtype="uint8")
mask[labels == label] = 255
# Find contours and determine contour area
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
c = max(cnts, key=cv2.contourArea)
color = list(np.random.random(size=3) * 256)
cv2.drawContours(image, [c], -1, color, 4)
cv2.imshow('image', image)
cv2.waitKey()
以下是其他参考资料:
- nathancy
1
2好的参考资料!你能分享一下输入图像和输出图像吗?我认为这样可以让人们更容易地欣赏你的算法。 - karlphillip
1
似乎你对对象有一个模式,这些对象有时会重叠。我建议你使用对象模式卷积图像,然后处理输出得分图像。
更详细地说:
假设为简单起见,您的初始图像只有一个通道。您正在寻找的对象看起来像这样: 。这是我们的模式。假设其大小为[W_p,H_p]。
。这是我们的模式。假设其大小为[W_p,H_p]。
第一步:构建新图像 - 得分 - 其中每个像素S在得分中=此像素是模式中心的概率。
一种方法是:对于原始图像中的每个像素P,“剪切”围绕P的[W_p,H_p]补丁(例如img(Rect(P-W_p/2,P-H_p/2,W_p,H_p))),并从模式中减去补丁以找到它们之间的“距离”(例如opencv中的cv::sum(cv::absdiff(patch, pattern))函数),并将此总和保存到S中。
另一种方法是:S = P.clone(); pattern = pattern / cv::sum(pattern); 然后使用cv::filter2D对S进行模式匹配...
现在,您应该过滤掉错误的正例: 1. 取得分最高的前2%(一种方法是使用cv :: calcHist) 2. 对于每个具有[W_p,H_p]内高得分邻居的像素-将此像素变为零!
现在,您应该只保留图像中模式中心具有某些值的零图像。万岁!
如果您事先不知道对象的外观,则可以使用轮廓找到一个对象,然后使用其轮廓的凸包(+边界框)“削减”它,并将其用作查找其余部分的卷积核。
更详细地说:
假设为简单起见,您的初始图像只有一个通道。您正在寻找的对象看起来像这样:
。这是我们的模式。假设其大小为[W_p,H_p]。第一步:构建新图像 - 得分 - 其中每个像素S在得分中=此像素是模式中心的概率。
一种方法是:对于原始图像中的每个像素P,“剪切”围绕P的[W_p,H_p]补丁(例如img(Rect(P-W_p/2,P-H_p/2,W_p,H_p))),并从模式中减去补丁以找到它们之间的“距离”(例如opencv中的cv::sum(cv::absdiff(patch, pattern))函数),并将此总和保存到S中。
另一种方法是:S = P.clone(); pattern = pattern / cv::sum(pattern); 然后使用cv::filter2D对S进行模式匹配...
现在,您应该过滤掉错误的正例: 1. 取得分最高的前2%(一种方法是使用cv :: calcHist) 2. 对于每个具有[W_p,H_p]内高得分邻居的像素-将此像素变为零!
现在,您应该只保留图像中模式中心具有某些值的零图像。万岁!
如果您事先不知道对象的外观,则可以使用轮廓找到一个对象,然后使用其轮廓的凸包(+边界框)“削减”它,并将其用作查找其余部分的卷积核。
- Shmuel Fine
2
你说过“要用一个物体模式卷积你的图像,然后处理输出得分图像”。也许你能指出必要的方法吗? - AlmostAI
我已经编辑了我的回答并提供了一些通用指南。现在好一些了吗? - Shmuel Fine
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接