我有许多数据集,其中包含已知的异常值(大额订单)。
data <- matrix(c("08Q1","08Q2","08Q3","08Q4","09Q1","09Q2","09Q3","09Q4","10Q1","10Q2","10Q3","10Q4","11Q1","11Q2","11Q3","11Q4","12Q1","12Q2","12Q3","12Q4","13Q1","13Q2","13Q3","13Q4","14Q1","14Q2","14Q3","14Q4","15Q1", 155782698, 159463653.4, 172741125.6, 204547180, 126049319.8, 138648461.5, 135678842.1, 242568446.1, 177019289.3, 200397120.6, 182516217.1, 306143365.6, 222890269.2, 239062450.2, 229124263.2, 370575384.7, 257757410.5, 256125841.6, 231879306.6, 419580274, 268211059, 276378232.1, 261739468.7, 429127062.8, 254776725.6, 329429882.8, 264012891.6, 496745973.9, 284484362.55),ncol=2,byrow=FALSE)
这个特定系列的前11个异常值为:
outliers <- matrix(c("14Q4","14Q2","12Q1","13Q1","14Q2","11Q1","11Q4","14Q2","13Q4","14Q4","13Q1",20193525.68, 18319234.7, 12896323.62, 12718744.01, 12353002.09, 11936190.13, 11356476.28, 11351192.31, 10101527.85, 9723641.25, 9643214.018),ncol=2,byrow=FALSE)
有哪些方法可以考虑这些异常值来预测时间序列?
我已经尝试过用下一个最大的异常值替换(对数据集进行10次运行,每次用下一个最大值替换异常值,直到第10个数据集中所有异常值都被替换)。 我还尝试了简单地删除异常值(因此再次运行数据集10次,每次删除一个异常值,直到在第10个数据集中删除了所有10个异常值)。
我只想指出,删除这些大订单并不会完全删除数据点,因为该季度还会发生其他交易。
我的代码通过多个预测模型(ARIMA加权外样本、ARIMA加权内样本、ARIMA加权、ARIMA、加性Holt-Winters加权和乘性Holt-Winters加权)测试数据,因此需要一些可以适用于这些多个模型的东西。
这里还有几组我使用过的数据集,但我还没有这些系列的异常值。
data <- matrix(c("08Q1","08Q2","08Q3","08Q4","09Q1","09Q2","09Q3","09Q4","10Q1","10Q2","10Q3","10Q4","11Q1","11Q2","11Q3","11Q4","12Q1","12Q2","12Q3","12Q4","13Q1","13Q2","13Q3","13Q4","14Q1","14Q2","14Q3", 26393.99306, 13820.5037, 23115.82432, 25894.41036, 14926.12574, 15855.8857, 21565.19002, 49373.89675, 27629.10141, 43248.9778, 34231.73851, 83379.26027, 54883.33752, 62863.47728, 47215.92508, 107819.9903, 53239.10602, 71853.5, 59912.7624, 168416.2995, 64565.6211, 94698.38748, 80229.9716, 169205.0023, 70485.55409, 133196.032, 78106.02227), ncol=2,byrow=FALSE)
data <- matrix(c("08Q1","08Q2","08Q3","08Q4","09Q1","09Q2","09Q3","09Q4","10Q1","10Q2","10Q3","10Q4","11Q1","11Q2","11Q3","11Q4","12Q1","12Q2","12Q3","12Q4","13Q1","13Q2","13Q3","13Q4","14Q1","14Q2","14Q3",3311.5124, 3459.15634, 2721.486863, 3286.51708, 3087.234059, 2873.810071, 2803.969394, 4336.4792, 4722.894582, 4382.349583, 3668.105825, 4410.45429, 4249.507839, 3861.148928, 3842.57616, 5223.671347, 5969.066896, 4814.551389, 3907.677816, 4944.283864, 4750.734617, 4440.221993, 3580.866991, 3942.253996, 3409.597269, 3615.729974, 3174.395507),ncol=2,byrow=FALSE)
如果这太复杂了,那就解释一下如何在R中使用某些命令检测到异常值后处理数据进行预测。例如平滑等等,以及我如何编写代码来处理它(而不使用检测异常值的命令)。
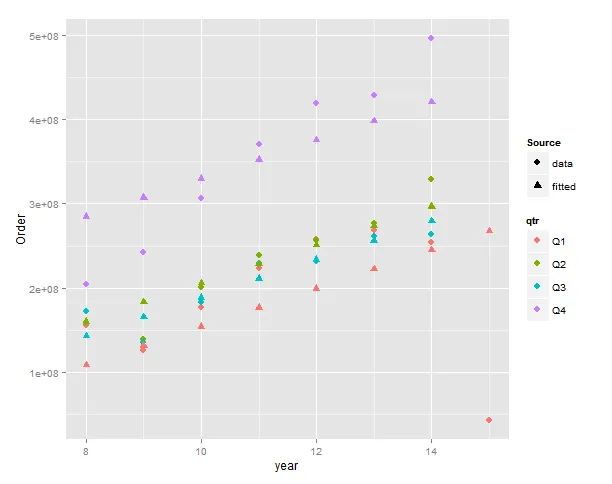
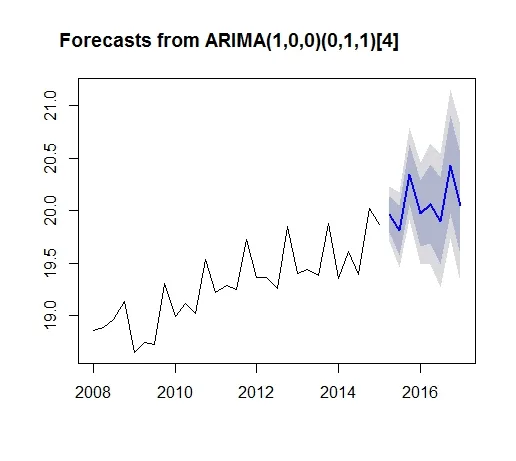
- 由于记录数量很少,平滑技术可能更好。霍尔特-温特斯、指数平滑、移动平均等方法比ARIMA建模更好。不过,我强烈建议使用月度数据,相信您能够获得它们。
- 总之,目前不确定您的数据是否有很多异常值,但模型和数据可能需要修订。
- Jaehyeon Kim